Conception d’une base de données¶
Ce chapitre est consacré la démarche de conception d’une base relationnelle. Elle se déroule en général selon un processus de conception comportant plusieurs étapes. Nous nous concentrons dans ce chapitre sur la modélisation, et sur la représentation de cette modélisation avec une notation très répandue, dite entité / association. Au préalable, nous allons discuter de l’objectif final, qui est d’obtenir un schéma de la base de données conforme au besoin et ne présentant par d’anomalie.
S1: La normalisation¶
La conception d’un schéma relationnel ne présente pas de difficulté technique. On constate en pratique qu’elle demande une certaine expérience, notamment parce que les conseils d’usage, assez abstraits, deviennent beaucoup plus clairs quand on s’est trompé une ou deux fois et qu’on a constaté les conséquences de ses erreurs. Le schéma de données constitue en effet les fondations d’une application Le schéma n’est jamais figé : il évoluera avec l’application. Mais la partie existante d’un schéma est toujours difficile à remettre en cause sans entraîner une réécriture non négligeable.
Etant donné un schéma et ses dépendances fonctionnelles, nous savons déterminer s’il est normalisé. Peut-on aller plus loin et produire automatiquement un schéma normalisé à partir de l’ensemble des attributs et de leurs contraintes (les DFs)? En principe oui, en pratique pas vraiment.
La décomposition d’un schéma¶
Regardons d’abord le principe avec un exemple illustrant la normalisation d’un schéma relationnel par un processus de décompo sition progressif. On veut représenter l’organisation d’un ensemble d’immeubles locatifs en appartements, et décrire les informations relatives aux propriétaires des immeubles et aux occupants de chaque appartement. Voici un premier schéma de relation :
Appart(id_appart, surface, id_immeuble, nb_etages, date_construction)
La clé est id_appart. Cette relation
est-elle normalisée ? Non, car l’identifiant de l’immeuble
détermine fonctionnellement le nombre d’étages et la date de construction. On
a donc une dépendance \(id\_immeuble \to nb\_étages,
date\_construction\) dont la partie gauche n’est pas la clé
id_appart. En pratique, une telle relation
dupliquerait le nombre d’étages et la date
de construction autant de fois qu’il y a d’appartements
dans un immeuble. Le bon schéma en l’occurrence serait la décomposition
en deux relations :
Appart(id_appart, surface, id_immeuble)
Immeuble (id_immeuble, nb_etages, date_construction)
Supposons qu’un immeuble puisse être détenu par plusieurs propriétaires, et considérons la seconde relation suivante,:
Proprietaire(id_appart, id_personne, quote_part)
Est-elle normalisée ? Oui car l’unique dépendance fonctionnelle est
Un peu de réflexion suffit à se convaincre
que ni l’appartement, ni le propriétaire ne déterminent
à eux seuls la quote-part. Seule l’association des deux
permet de donner un sens à cette information, et la
clé est donc le couple (id_appart, id_personne). Maintenant
considérons l’ajout du nom et du prénom
du propriétaire dans la relation.
Proprietaire(id_appart, id_personne, prenom, nom, quote_part)
La dépendance fonctionnelle \(id\_personne \to prénom, nom\) indique que cette relation n’est pas normalisée. Le bon schéma est :
Proprietaire(id_appart, id_personne, quote_part)
Personne(id_personne, prenom, nom)
Si, en revanche, on décide qu’il ne peut y avoir qu’un propriétaire pour un
appartement et inversement, la quote-part devient inutile, une nouvelle
dépendance fonctionnelle \(id\_personne \to id\_appart\) apparaît, et la
relation avant décomposition est bien normalisée, avec pour clé
id_personne.
Voyons pour finir le cas des occupants d’un appartement, avec la relation suivante.
Occupant(id_personne, nom, prenom, id_appart, surface)
On mélange clairement des informations sur les personnes,
et d’autres sur les appartements. Plus précisément,
la clé est le couple (id_personne, id_appart), mais
on a les dépendances suivantes :
- \(id\_personne \to prénom, nom\)
- \(id\_appart \to surface\)
Un premier réflexe pourrait être de décomposer en deux relations
Personne(id_personne, prénom, nom)
et Appart (id_appart, surface). Toutes
deux sont normalisées, mais
on perd alors une information importante, et même
essentielle : le fait que telle personne occupe
tel appartement. Il faut donc impérativement conserver
une relation correspondant à la clé initiale:Occupant (id_personne, id_appart). D’où
le schéma final :
Immeuble (id_immeuble, nb_etages, date_construction)
Proprietaire(id_appart, id_personne, quote_part)
Personne (id_personne, prenom, nom)
Appart (id_appart, surface)
Occupant (id_personne, id_appart)
Ce schéma, obtenu par décompositions successives, présente la double propriété
- de ne pas avoir perdu d’information par rapport à la version initiale;
- de ne contenir que des relations normalisées.
Important
L’absence de perte d’information est une notion qui est survolée ici mais qui est de fait essentielle. Une décomposition est sans perte d’information s’il est possible, par des opérations, de reconstruire la relation initiale, avant décomposition. Ces opérations, et notamment la jointure, seront présentés dans les chapitres suivants.
Cet exemple est une démonstration d’une approche quasiment algorithmique pour obtenir un schéma normalisé à partir d’un ensemble d’attributs initial. Cette approche est malheureusement inutilisable en pratique à cause d’une difficulté que nous avons cachée: les dépendances fonctionnelles présentes dans notre schéma ont été artificiellement créées par ajout d’identifiants pour les immeubles, les occupants et les appartements. En pratique, de tels identifiants n’existent pas si on n’a pas au préalable déterminé les « entités » présentes dans le schéma: Immeuble, Occupant, et Appartement. En d’autres termes, l’exemple qui précède s’appuie sur une forme de tricherie: on a normalisé un schéma dans lequel on avait guidé à l’avance la décomposition.
Une approche pratique¶
Reprenons notre table des films pour nous confronter à une situation réaliste. Rappelons les quelques attributs considérés.
(titre, annee, prenomMes, nomMES, anneeNaiss)
La triste réalité est qu’on ne trouve aucune dépendance fonctionnelle dans cet ensemble d’attribut. Le titre d’un film ne détermine rien puisqu’il y a évidemment des films différents avec le même titre, Eventuellement, la paire (titre, année) pourrait déterminer de manière univoque un film, mais un peu de réflexion suffit à se convaincre qu’il est très possible de trouver deux films différents avec le même titre la même année. Et ainsi de suite: le nom du réalisateur ou même la paire (prénom, nom) sont des candidats très fragiles pour définir des dépendances fonctionnelles. En fait, on constate qu’il est très rare en pratique de trouver des DFs « naturelles » sur lesquelles on peut solidement s’appuyer pour définir un schéma.
Il nous faut donc une démarche différente consistant à créer artificiellement des DFs parmi les ensembles d’attributs. La connaissance des identifiants d’appartement, d’immeuble et de personne dans notre exemple précédent correspondait à une telle création artificielle: tous les attributs de, respectivement, Immeuble, Appartement et Personne dépendent fonctionnellement, par construction, de leurs identifiants respectifs, ajoutés au schéma.
Comment trouve-t-on ces identifiants? Par une démarche essentiellement différente de celle partant « de bas en haut », consistant à prendre un tas d’attributs et à les regrouper en relations. Au contraire, on part de groupes d’attributs appartenant à une même entité, à laquelle on ajoute un attribut-identifiant. La démarche consiste à:
- déterminer les « entités » (immeuble, personne, appartement, ou film et réalisateur) pertinents pour l’application;
- définir une méthode d’identification de chaque entité; en pratique on recourt à la définition d’un identifiant artificiel (il n’a aucun rôle descriptif) qui permet d’une part de s’assurer qu’une même « entité » est représentée une seule fois, d’autre part de référencer une entité par son identifiant.
- préserver le lien entre les entités sans introduire de redondance, par un mécanisme de référence basé sur la clé.
Voici une illustration informelle de la méthode, que nous reprendrons ensuite de manière plus détailée avec la notation Entité/association.
Commençons par les deux premières étapes. On va d’abord
distinguer la table des films et la table des réalisateurs. Ensuite,
on va ajouter à chaque table un attribut spécial,
l’identifiant, désigné par id.
Important
Le choix de l’identifiant est un sujet délicat. On peut arguer en effet que l’identifiant devrait être recherché dans les attributs existant, au lieu d’en créer un artificiellement. Pour des raisons qui tiennent à la rareté/fragilité des DFs « naturelles », la création de l’identifiant artificiel est la seule réellement applicable et satisfaisante dans tous les cas.
On obtient le résultat suivant.
| id | titre | année |
|---|---|---|
| 1 | Alien | 1979 |
| 2 | Vertigo | 1958 |
| 3 | Psychose | 1960 |
| 4 | Kagemusha | 1980 |
| 5 | Volte-face | 1997 |
| 6 | Pulp Fiction | 1995 |
| 7 | Titanic | 1997 |
| 8 | Sacrifice | 1986 |
La table des films.
| id | titre | année | |
|---|---|---|---|
| 101 | Scott | Ridley | 1943 |
| 102 | Hitchcock | Alfred | 1899 |
| 103 | Kurosawa | Akira | 1910 |
| 104 | Woo | John | 1946 |
| 105 | Tarantino | Quentin | 1963 |
| 106 | Cameron | James | 1954 |
| 107 | Tarkovski | Andrei | 1932 |
La table des réalisateurs
Premier progrès : il n’y a maintenant plus de redondance dans la base de données. Le réalisateur Hitchcock, par exemple, n’apparaît plus qu’une seule fois, ce qui élimine les anomalies de mise à jour évoquées précédemment.
Important
On peut noter que, par construction, les schémas obtenus sont normalisés.
Il reste à représenter le lien entre les films et les metteurs
en scène, sans introduire de redondance. Maintenant que nous avons
défini les identifiants, il existe un moyen simple pour indiquer
quel est le metteur en scène qui a réalisé un film :
associer l’identifiant du metteur en scène au film. L’identifiant sert
alors de référence à l’entité. On ajoute un
attribut idRéalisateur dans la table Film, et on obtient la
représentation suivante.
| id | titre | année | idRéalisateur |
|---|---|---|---|
| 1 | Alien | 1979 | 101 |
| 2 | Vertigo | 1958 | 102 |
| 3 | Psychose | 1960 | 102 |
| 4 | Kagemusha | 1980 | 103 |
| 5 | Volte-face | 1997 | 104 |
| 6 | Pulp Fiction | 1995 | 105 |
| 7 | Titanic | 1997 | 106 |
| 8 | Sacrifice | 1986 | 107 |
Cette représentation est correcte. La redondance est réduite au minimum puisque seule l’identifiant du metteur en scène a été déplacé dans une autre table. Pour peu qu’on s’assure que cet identifiant ne change jamais, cette redondance n’induit aucun effet négatif. On peut vérifier que les anomalies que nous avons citées ont disparu.
D’une part, il n’y a plus de redondance des attributs descriptifs, donc toute mise à jour affecte l’unique occurrence de la donnée à modifier. D’autre part, on peut détruire un film sans affecter les informations sur le réalisateur. Ce gain dans la qualité du schéma n’a pas pour contrepartie une perte d’information. Il est en effet facile de voir que l’information initiale (autrement dit, avant la décomposition en deux tables) peut être reconstituée intégralement. En prenant un film, on obtient l’identifiant de son metteur en scène, et cette identifiant permet de trouver l’unique ligne dans la table des réalisateurs qui contient toutes les informations sur ce metteur en scène. Ce processus de reconstruction de l’information, dispersée dans plusieurs tables, peut s’exprimer avec les opérations relationnelles, et notamment la jointure.
Il reste à appliquer une méthode systématique visant à aboutir au résultat ci-dessus, et ce même dans des cas beaucoup plus complexes. Cela étant, aucune méthode ne produit automatiquement un résultat correct, puisqu’elle repose sur un processus d’analyse et d »identification des entités dont rien ne peut garantir la validité. On ne peut jamais se dispenser de réfléchir et de comprendre les données que l’on veut modéliser. Il faut, toujours, repérer les entités et leur attribuer un identifiant, et gérer correctement les références (ou associations) entre ces entités. Entités, associations, sont les concepts essentiels. D’où le modèle présenté dans ce qui suit.
S2: Le modèle Entité-Association¶
Le modèle Entité/Association (E/A) propose essentiellement une notation pour soutenir la démarche de conception de schéma présentée précédemment. La notation E/A a pour caractéristiques d’être simple et suffisamment puissante pour modéliser des structures relationnelles. De plus, elle repose sur une représentation graphique qui facilite considérablement sa compréhension.
Le modèle E/A souffre également de nombreuses insuffisances : la principale est de ne proposer que des structures. Il n’existe pas d’opération permettant de manipuler les données, et pas (ou peu) de moyen d’exprimer des contraintes. Un autre inconvénient du modèle E/A est de mener à certaines ambiguités pour des schémas complexes.
Le schéma de la base Films¶
La présentation qui suit est délibérement axée sur l’utilité du modèle E/A dans le cadre de la conception d’une base de données. Ajoutons qu’il ne s’agit pas directement de concevoir un schéma E/A (voir un cours sur les systèmes d’information), mais d’être capable de le comprendre et de l’interpréter. Nous reprenons l’exemple d’une base de données décrivant des films, avec leur metteur en scène et leurs acteurs, ainsi que les cinémas où passent ces films. Nous supposerons également que cette base de données est accessible sur le Web et que des internautes peuvent noter les films qu’ils ont vus.
La méthode permet de distinguer les entités qui constituent la base de données, et les associations entre ces entités. Un schéma E/A décrit l’application visée, c’est-à-dire une abstraction d’un domaine d’étude, pertinente relativement aux objectifs visés. Rappelons qu’une abstraction consiste à choisir certains aspects de la réalité perçue (et donc à éliminer les autres). Cette sélection se fait en fonction de certains besoins, qui doivent être précisément définis, et rélève d’une démarche d’analyse qui n’est pas abordée ici.
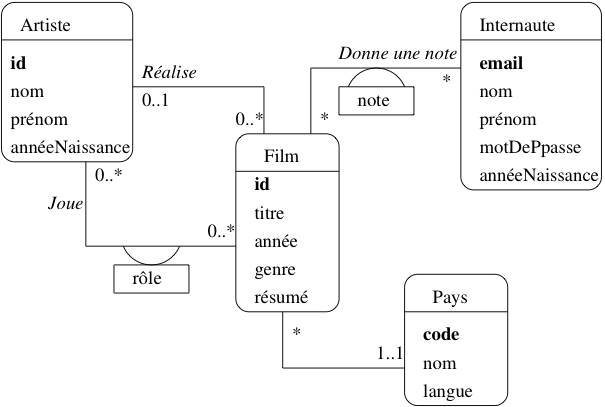
Fig. 6 Le schéma E/A des films
Par exemple, pour notre base de données Films, on n’a pas besoin de stocker dans la base de données l’intégralité des informations relatives à un internaute, ou à un film. Seules comptent celles qui sont importantes pour l’application. Voici le schéma décrivant cete base de données Films (figure Fig. 6). Sans entrer dans les détails pour l’instant, on distingue
- des entités, représentées par des rectangles, ici Film, Artiste, Internaute et Pays ;
- des associations entre entités représentées par des liens entre ces rectangles. Ici on a représenté par exemple le fait qu’un artiste joue dans des films, qu’un internaute note des films, etc.
Chaque entité est caractérisée par un ensemble d’attributs, parmi lesquels un ou plusieurs forment l’identifiant unique (en gras). Il est essentiel de dire ce qui caractérise de manière unique une entité, de manière à éviter la redondance d’information. Comme nous l’avons préconisé précédemment, un attribut non-descriptif a été ajouté à chaque entité, indépendamment des attributs « descriptifs ». Nous l’avons appelé id pour Film et Artiste, code pour le pays. Le nom de l’attribut-identifiant est peu important, même si la convention id est très répandue.
Seule exception: les internautes sont identifiés par un de leurs attributs descriptifs, leur adresse de courrier électronique. Même s’il s’agit en apparence d’un choix raisonnable (unicité de l’email pour identifier une personne), ce cas nous permettra d’illustrer les problèmes qui peuvent quand même se poser.
Les associations sont caractérisées par des cardinalités. La notation 0..* sur le lien Réalise, du côté de l’entité Film, signifie qu’un artiste peut réaliser plusieurs films, ou aucun. La notation 0..1 du côté Artiste signifie en revanche qu’un film ne peut être réalisé que par au plus un artiste. En revanche dans l’association Donne une note, un internaute peut noter plusieurs films, et un film peut être noté par plusieurs internautes, ce qui justifie l’a présence de 0..* aux deux extrêmités de l’association.
Le choix des cardinalités est essentiel. Ce choix est aussi parfois discutable, et constitue donc l’un des aspects les plus délicats de la modélisation. Reprenons l’exemple de l’association Réalise. En indiquant qu’un film est réalisé par un seul metteur en scène, on s’interdit les – pas si rares – situations où un film est réalisé par plusieurs personnes. Il ne sera donc pas possible de représenter dans la base de données une telle situation. Tout est ici question de choix et de compromis : est-on prêt en l’occurrence à accepter une structure plus complexe (avec 0..* de chaque côté) pour l’association Réalise, pour prendre en compte un nombre minime de cas ?
Les cardinalités sont notées par deux chiffres. Le chiffre de droite est la cardinalité maximale, qui vaut en général 1 ou . Le chiffre de gauche est la cardinalité minimale. Par exemple la notation 0..1 entre *Artiste et Film indique qu’on s’autorise à ne pas connaître le metteur en scène d’un film. Attention : cela ne signifie pas que ce metteur en scène n’existe pas. Une base de données, telle qu’elle est décrite par un schéma E/A, ne prétend pas donner une vision exhaustive de la réalité. On ne doit surtout pas chercher à tout représenter, mais s’assurer de la prise en compte des besoins de l’application.
La notation 1..1 entre Film et Pays indique au contraire que l’on doit toujours connaître le pays producteur d’un film. On devra donc interdire le stockage dans la base d’un film sans son pays.
Les cardinalités minimales sont moins importantes que les cardinalités maximales, car elles ont un impact limité sur la structure de la base de données et peuvent plus facilement être remises en cause après coup. Il faut bien être conscient de plus qu’elles ne représentent qu’un choix de conception, souvent discutable. Dans la notation UML que nous présentons ici, il existe des notations abrégées qui donnent des valeurs implicites aux cardinalités minimales :
- La notation * est équivalente à 0..* ;
- la notation 1 est équivalente à 1..1 .
Outre les propriétés déjà évoquées (simplicité, clarté de lecture), évidentes sur ce schéma, on peut noter aussi que la modélisation conceptuelle est totalement indépendante de tout choix d’implantation. Le schéma de la figure Le schéma E/A des films ne spécifie aucun système en particulier. Il n’est pas non plus question de type ou de structure de données, d’algorithme, de langage, etc. En principe, il s’agit donc de la partie la plus stable d’une application. Le fait de se débarrasser à ce stade de la plupart des considérations techniques permet de se concentrer sur l’essentiel : que veut-on stocker dans la base ?
Une des principales difficultés dans le maniement des schémas E/A est que la qualité du résultat ne peut s’évaluer que par rapport à une demande qui est difficilement formalisable. Il est donc souvent difficile de mesurer (en fonction de quels critères et quelle métrique ?) l’adéquation du résultat au besoin. Peut-on affirmer par exemple que :
- toutes les informations nécessaires sont représentées ?
- qu’un film ne sera jamais réalisé par plus d’un artiste ?
Il faut faire des choix, en connaissance de cause, en sachant toutefois qu’il est toujours possible de faire évoluer une base de données, quand cette évolution n’implique pas de restructuration trop importante. Pour reprendre les exemples ci-dessus, il est facile d’ajouter des informations pour décrire un film ou un internaute ; il serait beaucoup plus difficile de modifier la base pour qu’un film passe de un, et un seul, réalisateur, à plusieurs. Quant à changer l’identifiant de la table Internaute, c’est une des évolutions les plus complexes à réaliser. Les cardinalités et le choix des clés font vraiment partie des aspects décisifs des choix de conception.
Entités, attributs et identifiants¶
Il est difficile de donner une définition très précise des entités. Les points essentiels sont résumés ci-dessous.
Définition: Entités
On désigne par entité toute unité d’information identifiable et pertinente pour l’application.
La notion d’unité d’information correspond au fait qu’une entité ne peut pas se décomposer sans perte de sens. Comme nous l’avons vu précédemment, l’identité est primordiale. C’est elle qui permet de distinguer les entités les unes des autres, et donc de dire qu’une information est redondante ou qu’elle ne l’est pas. Il est indispensable de prévoir un moyen technique pour pouvoir effectuer cette distinction entre entités au niveau de la base de données : on parle d’identifiant ou (dans un contexte de base de données) de clé. Reportez-vous au début du chapitre pour une définition précise de cette notion.
La pertinence est également importante : on ne doit prendre en compte que les informations nécessaires pour satisfaire les besoins. Par exemple :
- le film Impitoyable ;
- l’acteur Clint Eastwood ;
sont des entités pour la base Films.
La première étape d’une conception consiste à identifier les entités utiles. On peut souvent le faire en considérant quelques cas particuliers. La deuxième est de regrouper les entités en ensembles : en général on ne s’intéresse pas à un individu particulier mais à des groupes. Par exemple il est clair que les films et les acteurs constituent des ensembles distincts d’entités. Qu’en est-il de l’ensemble des réalisateurs et de l’ensemble des acteurs ? Doit-on les distinguer ou les assembler ? Il est certainement préférable de les assembler, puisque des acteurs peuvent aussi être réalisateurs.
Attributs
Les entités sont caractérisées par des attributs (ou propriétés): le titre (du film), le nom (de l’acteur), sa date de naissance, l’adresse, etc. Le choix des attributs relève de la même démarche d’abstraction qui a dicté la sélection des entités : il n’est pas nécéssaire de donner exhaustivement tous les attributs d’une entité. On ne garde que ceux utiles pour l’application.
Un attribut est désigné par un nom et prend sa valeur dans un domaine comme les entiers, les chaînes de caractères, les dates, etc. On peut considérer un nom d’atribut \(A\) comme une fonction définie sur un ensemble d’entités \(E\) et prenant ses valeurs dans un domaine \(A\) pour une entité \(E\).
Selon cette définition un attribut prend une valeur et une seule. On dit que les attributs sont atomiques. Il s’agit d’une restriction importante puisqu’on s’interdit, par exemple, de définir un attribut téléphones d’une entité Personne, prenant pour valeur les numéros de téléphone d’une personne. Cette restricion est l’un des inconvénients du modèle relationnel, qui mène à la multiplication des tables par le mécanisme de normalisation dérit en début de chapitre. Pour notre exemple, il faudrait par exemple définir une table dédiée aux numéros de téléphone et associée aux personnes.
Note
Certaines méthodes admettent l’introduction de constructions plus complexes :
- les attributs multivalués sont constitués d’un ensemble de valeurs prises dans un même domaine ; une telle construction permet de résoudre le problème des numéros de téléphones multiples ;
- les attributs composés sont constitués par agrégation d’autres atributs ; un attribut adresse peut par exemple être décrit comme l’agrégation d’un code postal, d’un numéro de rue, d’un nom de rue et d’un nom de ville.
Cette modélisation dans le modèle conceptuel (E/A) doit pouvoir être transposée dans la base de données. Certains systèmes relationnels (PostgreSQL par exemple) autorisent des attributs complexes. Une autre solution est de recourir à d’autres modèles, semi-structurés ou objets.
Nous nous en tiendrons pour l’instant aux attributs atomiques qui, au moins dans le contexte d’une modélisation orientée vers un SGBD relationnel, sont suffisants.
Types d’entités¶
Il est maintenant possible de décrire un peu plus précisément les entités par leur type.
Définition: Type d’entité
Le type d’une entité est composé des éléments suivants :
- son nom ;
- la liste de ses attributs avec, – optionnellement – le domaine où l’attribut prend ses valeurs : les entiers, les chaînes de caractères ;
- l’indication du (ou des) attribut(s) permettant d’identifier l’entité : ils constituent la clé.
On dit qu’une entité e est une instance de son type E. Enfin, un ensemble d’entités \(\{e_1, e_2, \ldots e_n\}\), instances d’un même type \(E\) est une extension de \(E\).
Rappelons maintenant la notion de clé, pratiquement identique à celle énoncée pour les shémas relationnels.
Définition: clé
Soit \(E\) un type d’entité et \(A\) l’ensemble des attributs de \(E\). Une clé de \(E\) est un sous-ensemble minimal de \(A\) permettant d’identifier de manière unique une entité parmi n’importe quelle extension de \(E\).
Prenons quelques exemples pour illustrer cette définition.
Un internaute est caractérisé par plusieurs attributs : son
email, son nom, son prénom, la région où il habite.
L’adresse mail constitue une clé naturelle puisqu’on ne trouve pas, en principe,
deux internautes ayant la même adresse électronique.
En revanche l’identification par le nom seul paraît impossible puisqu’on
constituerait facilement un ensemble
contenant deux internautes avec le même nom.
On pourrait penser à utiliser la paire (nom,prénom),
mais il faut utiliser avec modération l’utilisation d’identifiants composés de plusieurs
attributs. Quoique possible, elle peut poser des problèmes de
performance et complique les manipulations par SQL.
Il est possible d’avoir plusieurs clés candidates pour un même ensemble d’entités. Dans ce cas on en choisit une comme clé principale (ou primaire), et les autres comme clés secondaires. Le choix de la clé (primaire) est déterminant pour la qualité du schéma de la base de données. Les caractéristiques d’une bonne clé primaire sont les suivantes :
- elle désigne sans ambiguité une et une seule entité dans toute extension;
- sa valeur est connue pour toute entité ;
- on ne doit jamais avoir besoin de la modifier ;
- enfin, pour des raisons de performance, sa taille de stockage doit être la plus petite possible.
Il est très difficile de trouver un ensemble d’attributs satisfaisant ces propriétés parmi les attributs descriptifs d’une entité. Considérons l’exemple des films. Le choix du titre pour identifier un film serait incorrect puisqu’on aura affaire un jour ou l’autre à deux films ayant le même titre. Même en combinant le titre avec un autre attribut (par exemple l’année), il est difficile de garantir l’unicité.
Le choix de l’adresse électronique (email) pour un internaute semble respecter ces conditions, du moins la première (unicité). Mais peut-on vraiment garantir que l’email sera connu au moment de la création de l’entité? De plus, il semble clair que cette adresse peut changer, ce qui va poser de gros problèmes puisque la clé, comme nous le verrons, sert à référencer une entité. Changer l’identifiant de l’entité implique donc de changer aussi toutes les références. La conclusion s’impose: ce choix d’identifiant est un mauvais choix, il posera à terme des problèmes pratiques.
Insistons: la seule solution saine et générique consiste à créer
un identifiant artificiel, indépendant de tout autre attribut. On peut ainsi
ajouter dans le type d’entité Film un attribut id, corespondant à un numéro
séquentiel qui sera incrémenté au fur et à mesure des insertions. Ce choix est de fait
le meilleur, dès lors qu’un attribut ne respecte pas les conditions ci-dessus
(autrement dit, toujours). Il satisfait
ces conditions: on
peut toujours lui attribuer une valeur, il ne sera jamais nécessaire
de la modifier, et elle a une représentation compacte.
On représente graphiquement un type d’entité comme sur la figure Représentation des types d’entité qui donne l’exemple des types Internaute et Film. L’attribut (ou les attributs s’il y en a plusieurs) formant la clé sont en gras.
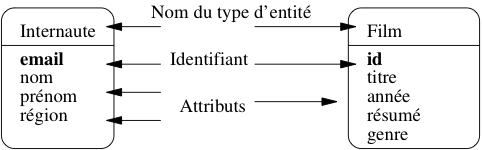
Fig. 7 Représentation des types d’entité
Il est important de bien distinguer types d’entités et entités. La distinction est la même qu’entre entre type et valeur dans un langage de programmation, ou schéma et *base dans un SGBD, comme nous le verrons.
Associations binaires¶
La représentation (et le stockage) d’entités indépendantes les unes des autres est de peu d’utilité. On va maintenant décrire les relations (ou associations) entre des ensembles d’entités.
Définition: association
Une association binaire entre les ensembles d’entités \(E_1\) et \(E_1\) est un ensemble de couples \((e_1, e_2)\), avec \(e_1 \in E_1\) et \(e_2 \in E_2\).
C’est la notion classique, ensembliste, de relation. On emploie plutôt le terme d’association pour éviter toute confusion avec le modèle relationnel. Une bonne manière d’interpréter une association entre des ensembles d’entités est de faire un petit graphe où on prend quelques exemples, les plus généraux possibles.
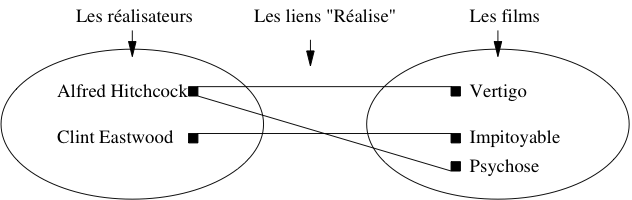
Fig. 8 Association entre deux ensembles
Prenons l’exemple de l’association représentant le fait qu’un réalisateur met en scène des films. Sur le graphe de la figure Association entre deux ensembles on remarque que :
- certains réalisateurs mettent en scène plusieurs films ;
- inversement, un film est mis en scène par au plus un réalisateur.
La recherche des situations les plus générales possibles vise à s’assurer que les deux caractéristiques ci-dessus sont vraies dans tout les cas. Bien entendu on peut trouver x % des cas où un film a plusieurs réalisateurs, mais la question se pose alors : doit-on modifier la structure de notre base, pour x % des cas. Ici, on a décidé que non. Encore une fois on ne cherche pas à représenter la réalité dans toute sa complexité, mais seulement la partie de cette réalité que l’on veut stocker dans la base de données.
Ces caractéristiques sont essentielles dans la description d’une association entre des ensembles d’entités.
Définition: cardinalités
Soit une association \((E_1, E_2)\) entre deux types d’entités. La cardinalité de l’association pour \(E_i, i \in \{1, 2\}\), est une paire \([min, max]\) telle que :
Le symbole max (cardinalité maximale) désigne le nombre maximal de fois où une une entité \(e_i\) peut intervenir dans l’association.
En général, ce nombre est 1 (au plus une fois) ou \(n\) (plusieurs fois, nombre indeterminé), noté par le symbole *.
Le symbole min (cardinalité minimale) désigne le nombre minimal de fois où une une entité \(e_i\) peut intervenir dans l’association.
En général, ce nombre est 1 (au moins une fois) ou 0.
Les cardinalités maximales sont plus importantes que les cardinalités minimales ou, plus précisément, elles s’avèrent beaucoup plus difficiles à remettre en cause une fois que le schéma de la base est constitué. On décrit donc souvent une association de manière abrégée en omettant les cardinalités minimales. La notation * en UML, est l’abréviation de 0..*, et 1 est l’abréviation de 1..1. On caractérise également une association de manière concise en donnant les cardinalités maximales aux deux extrêmités, par exemple 1:* (association de un à plusieurs) ou *:* (association de plusieurs à plusieurs).
Les cardinalités minimales sont parfois désignées par le terme contraintes de participation. La valeur 0 indique qu’une entité peut ne pas participer à l’association, et la valeur 1 qu’elle doit y participer.
Insistons sur le point suivant : les cardinalités n’expriment pas une vérité absolue, mais des choix de conception. Elles ne peuvent être déclarés valides que relativement à un besoin. Plus ce besoin sera exprimé précisément, et plus il sera possible d’appécier la qualité du modèle.
Il existe plusieurs manières de noter une association entre types d’entités. Nous utilisons ici la notation de la méthode UML. En France, on utilise aussi couramment – de moins en moins… – la notation de la méthode MERISE que nous ne présenterons pas ici.
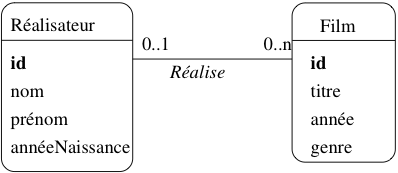
Fig. 9 Représentation de l’association
Dans la notation UML, on indique les cardinalités aux deux extrêmités d’un lien d’association entre deux types d’entités \(T_A\) et \(T_B\). Les cardinalités pour \(T_A\) sont placées à l’extrémité du lien allant de \(T_A\) à \(T_B\) et les cardinalités pour \(T_B\) sont l’extrémité du lien allant de \(T_B\) à \(T_A\).
Pour l’association entre Réalisateur et Film, cela donne l’association de la figure Représentation de l’association. Cette association se lit Un réalisateur réalise zéro, un ou plusieurs films, mais on pourrait tout aussi bien utiliser la forme passive avec comme intitulé de l’association Est réalisé par et une lecture Un film est réalisé par au plus un réalisateur. Le seul critère à privilégier dans ce choix des termes est la clarté de la représentation.
Prenons maintenant l’exemple de l’association (Acteur, Film) représentant le fait qu’un acteur joue dans un film. Un graphe basé sur quelques exemples est donné dans la figure Association (Acteur,Film). On constate tout d’abord qu’un acteur peut jouer dans plusieurs films, et que dans un film on trouve plusieurs acteurs. Mieux : Clint Eastwood, qui apparaissait déjà en tant que metteur en scène, est maintenant également acteur, et dans le même film.
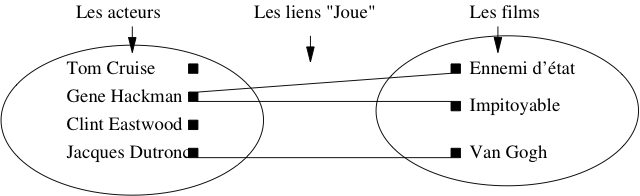
Fig. 10 Association (Acteur,Film)
Cette dernière constatation mène à la conclusion qu’il vaut mieux regrouper les acteurs et les réalisateurs dans un même ensemble, désigné par le terme plus général « Artiste ». On obtient le schéma de la figure Association entre Artiste et Film, avec les deux associations représentant les deux types de lien possible entre un artiste et un film : il peut jouer dans le film, ou le réaliser. Ce « ou » n’est pas exclusif : Eastwood joue dans Impitoyable, qu’il a aussi réalisé.
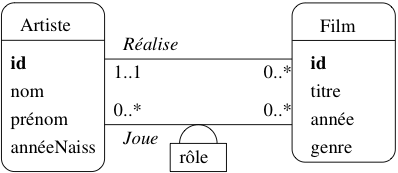
Fig. 11 Association entre Artiste et Film
Dans le cas d’associations avec des cardinalités multiples de chaque côté, on peut avoir des attributs qui ne peuvent être affectés qu’à l’association elle-même. Par exemple l’association Joue a pour attribut le rôle tenu par l’acteur dans le film (figure Association entre Artiste et Film).
Rappelons qu’un attribut ne peut prendre qu’une et une seule valeur.
Clairement, on ne peut associer rôle ni à Acteur
puisqu’il a autant de valeurs possibles qu’il y a de films
dans lesquels cet acteur a joué, ni à Film, la réciproque étant vraie également.
Seules les associations ayant des cardinalités multiples
de chaque côté peuvent porter des attributs.
Quelle est la clé d’une association ? Si l’on s’en tient à la définition, une association est un ensemble de couples, et il ne peut donc y avoir deux fois le même couple (parce qu’on ne trouve pas deux fois le même élément dans un ensemble). On a donc :
Définition: Clé d’une association
La clé d’une association (binaire) entre un type d’entité \(E_1\) et un type d’entité \(E_2\) est la paire constituée de la clé \(c_1\) de \(E_1\) et de la clé \(c_2\) de \(E_2\).
En pratique cette contrainte est souvent trop contraignante car on souhaite autoriser deux entités à être liées plus d’une fois dans une association. Imaginons par exemple qu’un internaute soit amené à noter à plusieurs reprises un film, et que l’on souhaite conserver l’historique de ces notations successives. Avec une association binaire entre Internaute et Film, c’est impossible : on ne peut définir qu’un seul lien entre un film donné et un internaute donné.
Le problème est qu’il n’existe pas de moyen pour distinguer des liens multiples entre deux mêmes entités. Le seul moyen pour effectuer une telle distinction est d’introduire une entité discriminante, par exemple la date de la notation. On obtient alors une association ternaire dans laquelle on a ajouté un type d’entité Date (figure Ajout d’une entité Date pour conserver l’historique des notations).
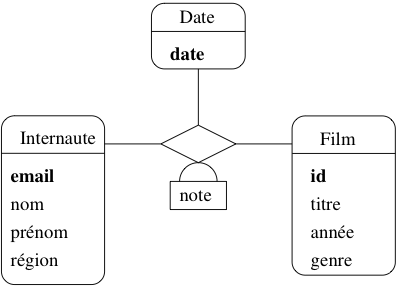
Fig. 12 Ajout d’une entité Date pour conserver l’historique des notations
Un lien de cette association réunit donc une
entité Film, une entité Internaute
et une entité Date. On peut identifier
un tel lien par un triplet (id, email, date)
constitué par les clés des trois entités constituant le lien.
Comme le montre la figure Graphe d’une association ternaire, il devient alors possible, pour un même internaute, de noter plusieurs fois le même film, pourvu que ce ne soit pas à la même date. Réciproquement un internaute peut noter des films différents le même jour, et un même film peut être noté plusieurs fois à la même date, à condition que ce ne soit pas par le même internaute.

Fig. 13 Graphe d’une association ternaire
Même si cette solution est correcte, elle présente
l’inconvénient d’introduire une entité assez artificielle,
Date, qui porte peu d’information et vient
alourdir le schéma. En pratique on s’autorise une notation
abrégée en ajoutant un attribut date dans
l’association, et en le soulignant pour indiquer
qu’il fait partie de la clé, en plus
du couple des clés des entités (voir figure Notation abrégée d’une association avec un type d’entité Date).
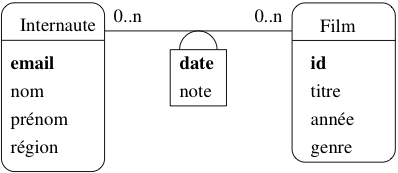
Fig. 14 Notation abrégée d’une association avec un type d’entité Date
Nous reviendrons plus longuement sur les associations ternaires par la suite.
Quiz¶
Exercices¶
S3: Concepts avancés¶
Entités faibles¶
Jusqu’à présent nous avons considéré le cas d’entités indépendantes les unes des autres. Chaque entité, disposant de son propre identifiant, pouvait être considérée isolément. Il existe des cas où une entité ne peut exister qu’en étroite association avec une autre, et est identifiée relativement à cette autre entité. On parle alors d’entité faible.
Prenons l’exemple d’un cinéma, et de ses salles. On peut considérer chaque salle comme une entité, dotée d’attributs comme la capacité, l’équipement en son Dolby, ou autre. Il est diffcilement imaginable de représenter une salle sans qu’elle soit rattachée à son cinéma. C’est en effet au niveau du cinéma que l’on va trouver quelques informations générales comme l’adresse de la salle.
Il est possible de représenter le lien en un cinéma et ses salles
par une association classique, comme le montre la figure Modélisations possibles du lien Cinéma-Salle.a.
La cardinalité 1..1 force la participation d’une salle
à un lien d’association avec un et un seul cinéma. Cette représentation
est correcte, mais présente un inconvénient : on doit créer
un identifiant artificiel id pour le type d’entité Salle,
et numéroter toutes les salles, indépendamment du cinéma auquel
elles sont rattachées.
On peut considérer qu’il est beaucoup plus naturel de numéroter les salles par un numéro interne à chaque cinéma. La clé d’identification d’une salle est alors constituée de deux parties :
- la clé de Cinéma, qui indique dans quel cinéma se trouve la salle ;
- le numéro de la salle au sein du cinéma.
En d’autres termes, l’entité Salle ne dispose pas d’une identification absolue, mais d’une identification relative à une autre entité. Bien entendu cela force la salle a toujours être associée à un et un seul cinéma.
La représentation graphique des entités faibles avec UML est illustrée
dans la figure Modélisations possibles du lien Cinéma-Salle.b. La salle est associée au cinéma
avec une association qualifiée par l’attribut no qui sert de discriminant
pour distinguer les salles au sein d’un même cinéma. Noter
que la cardinalité du côté Cinéma est implicitement 1..1.
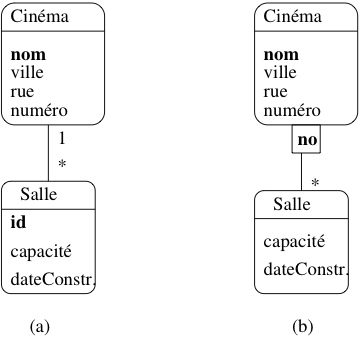
Fig. 15 Modélisations possibles du lien Cinéma-Salle
L’introduction d’entités faibles est un subtilité qui permet de capturer une caractéristique intéressante du modèle. Elle n’est pas une nécessité absolue puisqu’on peut très bien utiliser une association classique. La principale différence est que, dans le cas d’une entité faible, on obtient une identification composée qui peut être plus pratique à gérer, et peut également rendre plus faciles certaines requêtes. On touche ici à la liberté de choix qui est laissée, sur bien des aspects, à un « modeleur » de base de données, et qui nécessite de s’appuyer sur une expérience robuste pour apprécier les conséquences de telle ou telle décision.
La présence d’un type d’entité faible \(B\) associé à un type d’entité \(A\) implique également des contraintes fortes sur les créations, modifications et destructions des instances de \(A\) car on doit toujours s’assurer que la contrainte est valide. Concrètement, en prenant l’exemple de Salle et de Cinéma, on doit mettre en place les mécanismes suivants :
- quand on insère une salle dans la base, on doit toujours l’associer à un cinéma ;
- quand un cinéma est détruit, on doit aussi détruire toutes ses salles ;
- quand on modifie la clé d’un cinéma, il faut répercuter la modification sur toutes ses salles.
Réfléchissez bien à ces mécanismes pour apprécier le sucroît de contraintes apporté par des variantes des associations. Parmi les impacts qui en découlent, et pour respecter les règles de destruction/création énoncées, on doit mettre en place une stratégie. Nous verrons que les SGBD relationnels nous permettent de spécifier de telles stratégies.
Associations généralisées¶
On peut envisager des associations entre plus de deux entités, mais elles sont plus difficiles à comprendre, et surtout la signification des cardinalités devient beaucoup plus ambigue. La définition d’une association \(n\)-aire est une généralisation de celle des associations binaires.
Définition: associations n-aires
Une association n-aire entre n types d’entités \(E_1, E_2, \ldots E_n\) est un ensemble de n-uplets \((e_1, e_2, \ldots, e_n)\) où chaque \(e_i\) appartient à \(E_i\).
Il n’existe pas en principe pas de limite sur le degré d’une association. En pratique on ne va jamais au-delà d’une association entre trois entités qui est déjà assez difficile à interpréter.
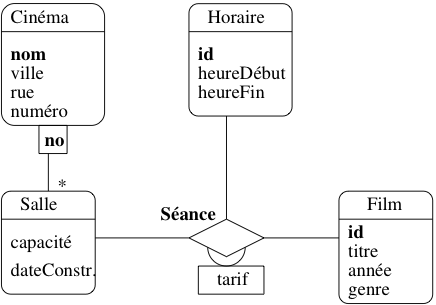
Fig. 16 Association ternaire représentant les séances
Nous allons prendre l’exemple d’une association permettant de représenter la projection de certains films dans des salles à certains horaires. Il s’agit d’une association ternaire entre les types d’entités Film, Salle et Horaire (figure Association ternaire représentant les séances). Chaque instance de cette association lie un film, un horaire et une salle. La figure Graphe d’une association ternaire montre quelques-unes de ces instances.
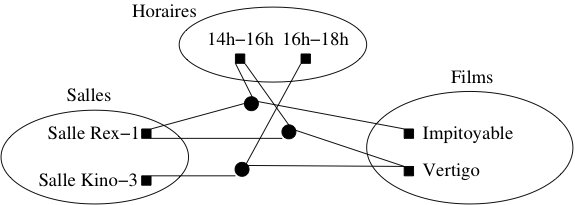
Fig. 17 Graphe d’une association ternaire
Bien que, jusqu’à présent, une association ternaire puisse être considérée comme une généralisation directe des associations binaires, en réalité de nouveaux problèmes sont soulevés.
Tout d’abord les cardinalités sont, implicitement, 0..*. Il n’est pas possible de dire qu’une entité ne participe qu’une fois à l’association. Il est vrai que, d’une part la situation se présente rarement, d’autre part cette limitation est due à la notation UML qui place les cardinalités à l’extrémité opposée d’une entité.
Plus problématique en revanche est la détermination de la clé. Qu’est-ce qui identifie un lien entre trois entités ? En principe, la clé est le triplet constitué des clés respectives de la salle, du film et de l’horaire constituant le lien. On aurait donc le \(n\)-uplet [nomCinéma, noSalle, idFilm, idHoraire]. Une telle clé est assez volumineuse, ce qui risque de poser des problèmes de performance. De plus elle ne permet pas d’imposer certaines contraintes comme, par exemple, le fait que dans une salle, pour un horaire donné, il n’y a qu’un seul film. Comme le montre la figure Graphe d’une association ternaire, il est tout à fait possible de créer deux liens distincts qui s’appuient sur le même horaire et la même salle.
Ajouter une telle contrainte, c’est signifier que la clé de l’association est en fait constitué de [nomCinéma, noSalle, idHoraire]. C’est donc un sous-ensemble de la concaténation des clés, ce qui semble rompre avec la définition donnée précédemment. On peut évidemment compliquer les choses en ajoutant une deuxième contrainte similaire, comme connaissant le cinéma, le film et l’horaire, je connais la salle. Il faut ajouter une deuxième clé [idFilm,idHoraire]. Il n’est donc plus possible de déduire automatiquement la clé comme on le faisait dans le cas des associations binaires. Plusieurs clés deviennent possibles : on parle de clé candidates.
Les associations de degré supérieur à deux sont difficiles à manipuler et à interpréter. Il est toujours possible de remplacer cette association par un type d’entité. Pour cela on suit la règle suivante :
Règle
Soit \(A\) une association entre les types d’entité \(\{E_1, E_2, \ldots, E_n\}\). La transformation de \(A\) en type d’entité s’effectue en trois étapes :
- On attribue un identifiant autonome à \(A\).
- On crée une association \(A_i\) de type “1:n” entre \(A\) et chacun des \(A_i\) La contrainte minimale, du côté de A, est toujours à 1.
L’association précédente peut être transformée en un type
d’entité Séance. On lui attribue un identifiant
idSéance, et des associations
“1..*” avec Film, Horaire et Salle.
Voir figure L’association Séance transformée en entité.
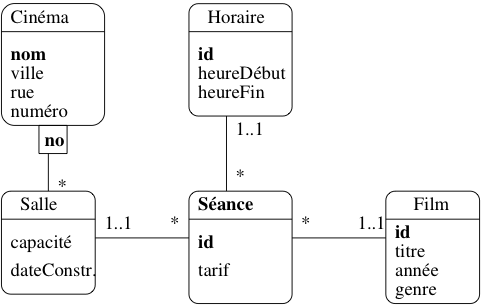
Fig. 18 L’association Séance transformée en entité
Spécialisation¶
Bilan¶
Le modèle Entité/Association est simple et pratique.
- Il n’y a que 3 concepts : entités, associations et attributs.
- Il est approprié à une représentation graphique intuitive, même s’il existe beaucoup de conventions.
- Il permet de modéliser rapidement des structures pas trop complexes.
Il présente malheureusement plusieurs limitations, qui découlent du fait que beaucoup de choix de conceptions plus ou moins équivalents peuvent découler d’une même spécification, et que la spécification elle-même est dans la plupart du cas informelle et sujette à interprétation.
Un autre inconvénient du modèle E/A reste sa pauvreté : il est difficile d’exprimer des contraintes d’intégrité, des structures complexes. Beaucoup d’extensions ont été proposées, mais la conception de schéma reste en partie matière de bon sens et d’expérience. On essaie en général :
- de se ramener à des associations entre 2 entités : au-delà, on a probablement intérêt a transformer l’association en entité ;
- d’éviter toute redondance : une information doit se trouver en un seul endroit ;
- enfin – et surtout – de privilégier la simplicité et la lisibilité, notamment en ne représentant que ce qui est strictement nécessaire.
La mise au point d’un modèle engage fortement la suite d’un projet de développement de base de données. Elle doit s’appuyer sur des personnes expérimentées, sur l’écoute des prescripteurs, et sur un processus par itération qui identifie les ambiguités et cherche à les résoudre en précisant le besoin correspondant. Dans le cadre des bases de données, le modèle E/A est utilisé dans la phase de conception. Il permet de spécifier la structure des informations qui vont être contenues dans la base et d’offrir une représentation abstraite indépendante du modèle logique qui sera choisi ensuite.
Signalons pour finir que les SGBD fournissent des outils de modélisation étroitement associés à la production et à la maintenance de la base. C’est le cas par exemple de MySQLWorkbench que vous pouvez librement récupérer et tester (https://www.mysql.fr/products/workbench/).
Quiz¶
Exercices¶

Ce cours de Philippe Rigaux est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
Table des Matières
- Introduction
- Le modèle relationnel
- SQL, langage déclaratif
- SQL, langage algébrique
- SQL, compléments
- SQL, ANCIENNE VERSION
- Conception d’une base de données
- Schémas relationnel
- Procédures et triggers
- Transactions
Recherche
Saisissez un ou plusieurs mots-clés.