Le langage PL/SQL¶
Le langage SQL n’est pas un langage de programmation au sens courant du terme. Il ne permet pas, par exemple, de définir des fonctions ou des variables, d’effectuer des itérations ou des instructions conditionnelles. Il ne s’agit pas d’un défaut dans la conception du langage, mais d’une orientation délibérée de SQL vers les opérations de recherche de données dans une base volumineuse, la priorité étant donnée à la simplicité et à l’efficacité*. Ces deux termes ont une connotation forte dans le contexte d’un langage d’interrogation, et correspondent à des critères (et à des contraintes) précisément définis. La simplicité d’un langage est essentiellement relative à son caractère déclaratif, autrement dit à la capacité d’exprimer des recherches en laissant au système le soin de déterminer le meilleur moyen de les exécuter. L’efficacité est, elle, définie par des caractéristiques liées à la complexité d’évaluation sur lesquelles nous ne nous étendrons pas ici. Signalons cependant que la terminaison d’une requête SQL est toujours garantie, ce qui n’est pas le cas d’un programme écrit dans un langage plus puissant, .
Il est donc clair que SQL ne suffit pas pour le développement d’applications, et tous les SGBD relationnels ont, dès l’origine, proposé des interfaces permettant de l’associer à des langages plus classiques comme le C ou Java. Ces interfaces de programmation permettent d’utiliser SQL comme outil pour récupérer des données dans des programmes réalisant des tâches très diverses : interfaces graphiques, traitements « batch », production de rapports ou de sites web, etc. D’une certaine manière, on peut alors considérer SQL comme une interface d’accès à la base de données, intégrée dans un langage de programmation généraliste. Il s’agit d’ailleurs certainement de son utilisation la plus courante.
Pour certaines fonctionnalités, le recours à un langage de programmation « externe » s’avère cependant inadapté ou insatisfaisant. Une évolution des SGBD consiste donc à proposer, au sein même du système, des primitives de programmation qui viennent pallier le manque relatif d’expressivité des langages relationnnels. Le présent chapitre décrit ces évolutions et leur application à la création de procédures stockées et de triggers. Les premières permettent d’enrichir un schéma de base de données par des calculs ou des fonctions qui ne peuvent pas - parfois même dans des cas très simples - être obtenus avec SQL ; les seconds étendent la possibilité de définir des contraintes.
Parallèlement à ces applications pratiques, les procédures stockées illustrent simplement les techniques d’intégration de SQL à un langage de programmation classique, et soulignent les limites d’utilisation d’un langage d’interrogation, et plus particulièrement du modèle relationnel.
S1. Procédures stockées¶
Supports complémentaires:
Comme mentionné ci-dessus, les procédures stockées constituent une alternative à l’écriture de programmes avec une langage de programmation généraliste. Commençons par étudier plus en détail les avantages et inconvénients respectifs des deux solutions avant d’entrer dans les détails techniques.
Rôle et fonctionnement des procédures stockées¶
Une procédure stockée s’exécute au sein du SGBD, ce qui évite les échanges réseaux qui sont nécessaires quand les mêmes fonctionnalités sont implantées dans un programme externe communiquant en mode client/serveur avec la base de données. La figure Comparaison programmes externes/procédures stockées illustre la différence entre les deux mécanismes. À gauche un programme externe, écrit par exemple en C, doit tout d’abord se connecter au serveur du SGBD. Le programme s’exécute alors en communiquant avec le serveur pour exécuter les requêtes et récupérer les résultats. Dans cette architecture, chaque demande d’exécution d’un ordre SQL implique une transmission sur le réseau, du programme vers le client, suivie d’une analyse de la requête par le serveur, de sa compilation et de son exécution (Dans certains cas les requêtes du programme client peuvent être précompilées, ou « préparées ». Ensuite, chaque fois que le programme client souhaite récupérer un n-uplet du résultat, il doit effectuer un appel externe, via le réseau. Tous ces échanges interviennent de manière non négligeable dans la performance de l’ensemble, et cet impact est d’autant plus élevé que les communications réseaux sont lentes et/ou que le nombre d’appels nécessaires à l’exécution du programme est important.
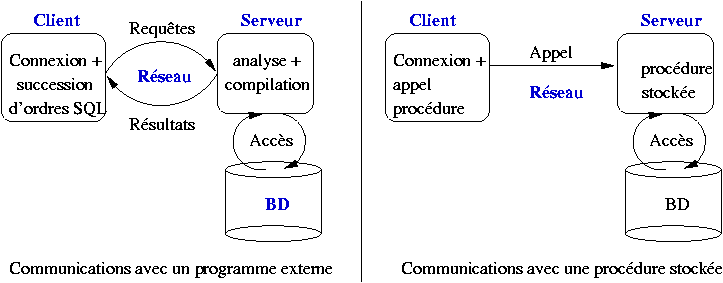
Fig. 20 Comparaison programmes externes/procédures stockées
Le recours à une procédure stockée permet de regrouper du côté serveur l’ensemble des requêtes SQL et le traitement des données récupérées. La procédure est compilée une fois par le SGBD, au moment de sa création, ce qui permet de l’exécuter rapidement au moment de l’appel. De plus les échanges réseaux ne sont plus nécessaires puisque la logique de l’application est étroitement intégrée aux requêtes SQL. Le rôle du programme externe se limite alors à se connecter au serveur et à demander l’exécution de la procédure, en lui passant au besoin les paramètres nécessaires.
Bien entendu, en pratique, les situations ne sont pas aussi tranchées et le programme externe est en général amené à appeler plusieurs procédures, jouant en quelque sorte le rôle de coordinateur. Si les performances du système sont en cause, un recours judicieux aux procédures stockées reste cependant un bon moyen de réduire le trafic client-serveur.
L’utilisation de procédures stockées est par ailleurs justifiée, même en l’absence de problèmes de performance, pour des fonctions très « sensibles », terme qui recouvre (non exclusivement) les cas suivants :
- la fonction est basée sur des règles complexes qui doivent être implantées très soigneusement ;
- la fonction met à jour des données dont la correction et la cohérence sont indispensable au bon fonctionnement de l’application ;
- la fonction évolue souvent.
On est souvent amené, quand on développe une application, à utiliser plusieurs langages en fonction du contexte : le langage C ou Java pour les traitements batch, PHP ou Python pour l’interface web, un générateur d’application propriétaire pour la saisie et la consultation à l’écran, un langage de script pour la production de rapports, etc. Il est important alors de pouvoir factoriser les opérations de base de données partagées par ces différents contextes, de manière à les rendre disponibles pour les différents langages utilisés. Par exemple la réservation d’un billet d’avion, ou l’exécution d’un virement bancaire, sont des opérations dont le fonctionnement correct (pas deux billets pour le même siège ; pas de débit sans faire le crédit correspondant) et cohérent (les mêmes règles doivent être appliquées, quel que soit le contexte d’utilisation) doit toujours être assuré.
C’est facile avec une procédure stockée, et cela permet d’une part d’implanter une seule fois des fonctions « sensibles », d’autre part de garantir la correction, la cohérence et l’évolutivité en imposant l’utilisation systématique de ces fonctions au lieu d’un accès direct aux données.
Enfin, le dernier avantage des procédures stockées est la relative facilité de programmation des opérations de bases de données, en grande partie à cause de la très bonne intégration avec SQL. Cet aspect est favorable à la qualité et à la rapidité du développement, et aide également à la diffusion et à l’installation du logiciel puisque les procédures sont compilées par les SGBD et fonctionnent donc de manière identique sur toute les plateformes.
Il existe malheureusement une contrepartie à tous ces avantages : chaque éditeur de SGBD propose sa propre extension procédurale pour créer des procédures stockées, ce qui rend ces procédures incompatibles d’un système à un autre. Cela peut être dissuasif si on souhaite produire un logiciel qui fonctionne avec tous les SGBD relationnels.
La description qui suit se base sur le langage PL/SQL d’Oracle (« PL » signifie Procedural Language) qui est sans doute le plus riche du genre. Le même langage, simplifié, avec quelques variantes syntaxiques mineures, est proposé par PostgreSQL, et les exemples que nous donnons peuvent donc y être transposés sans trop de problème. Les syntaxes des langages utilisés par d’autres systèmes sont un peu différentes, mais tous partagent cependant un ensemble de concepts et une proximité avec SQL qui font de PL/SQL un exemple tout à fait représentatif de l’intérêt et de l’utilisation des procédures stockées.
Introduction à PL/SQL¶
Nous allons commencer par quelques exemples très simples, appliqués à la base Films, afin d’obtenir un premier aperçu du langage. Le premier exemple consiste en quelques lignes permettant d’afficher des statistiques sur la base de données (nombre de films et nombre d’artistes). Il ne s’agit pas pour l’instant d’une procédure stockée, mais d’un code qui est compilé et exécuté en direct.
-- Exemple de bloc PL/SQL donnant des informations sur la base
DECLARE
-- Quelques variables
v_nbFilms INTEGER;
v_nbArtistes INTEGER;
BEGIN
-- Compte le nombre de films
SELECT COUNT(*) INTO v_nbFilms FROM Film;
-- Compte le nombre d'artistes
SELECT COUNT(*) INTO v_nbArtistes FROM Artiste;
-- Affichage des résultats
DBMS_OUTPUT.PUT_LINE ('Nombre de films: ' || v_nbFilms);
DBMS_OUTPUT.PUT_LINE ('Nombre d''artistes: ' || v_nbArtistes);
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE ('Problème rencontré dans StatsFilms');
END;
/
Le code est structuré en trois parties
qui forment un « bloc » : déclarations des variables,
instructions (entre BEGIN et END) et gestion des exceptions.
La première remarque importante est que les variables sont typées, et que les
types sont exactement ceux de SQL (ou plus largement les types supportés par le
SGBD, qui peuvent différer légèrement de la norme). Un autre aspect de
l’intégration forte avec SQL est la possibilité d’effectuer des requêtes,
d’utiliser dans cette requête des critères basés sur la valeur des variables de
la procédure, et de placer le résultat dans une (ou plusieurs) variables grâce à
la clause INTO. En d’autres termes on transfère directement des
données représentées selon le modèle relationnel et accessibles avec SQL,
dans des unités d’information manipulables avec les structures classiques (test
ou boucles) d’un langage impératif.
Les fonctions SQL fournies par le SGBD sont également utilisables, ainsi que
des librairies spécifiques à la programmation procédurale (des packages
chez ORACLE). Dans l’exemple ci-dessus on utilise le package
DBMS_OUTPUT qui permet de produire des messages sur la sortie
standard (l’écran en général).
La dernière section du programme est celle qui gère les « exceptions ». Ce
terme désigne une erreur qui est soit définie par l’utilisateur en fonction de
l’application (par exemple l’absence d’un n-uplet, ou une valeur incorrecte
dans un attribut), soit engendrée par le système à l’exécution (par exemple une
division par zéro, ou l’absence d’une table). Au moment où une erreur est
rencontrée, PL/SQL redirige le flux d’exécution vers la section
EXCEPTION où le programmeur doit définir les actions à entreprendre au
cas par cas. Dans l’exemple précédent, on prend toutes les exceptions
indifféremment (mot-clé OTHERS qui désigne le choix par défaut) et on
affiche un message.
Note
Un programme Pl/SQL peut être placé dans un fichier
et executé avec la commande start sous l’utilitaire de commandes.
par exemple:
SQL>start StatsFilms
En cas d’erreur de compilation, la commande SHOW ERRORS donne la liste
des problèmes rencontrés. Sinon le code est exécuté. Voici par exemple ce que
l’on obtient avec le code donné précédemment en exemple (La commande
set serveroutput on assure que les messages sont bien affichés à
l’écran..
SQL> set serveroutput on
SQL> start StatsFilms
Nombre de films: 48
Nombre d'artistes: 126
Voici maintenant un exemple de procédure stockée. On retrouve la même structuration que précédemment (déclaractions, instructions, exception), mais cette fois ce « bloc » est nommé, stocké dans la base au moment de la compilation, et peut ensuite être appelé par son nom. La procédure implante la règle suivante : l’insertion d’un texte dans la table des genres s’effectue toujours en majuscules, et on vérifie au préalable que ce code n’existe pas déjà.
-- Insère un nouveau genre, en majuscules, et en vérifiant
-- qu'il n'existe pas déjà
CREATE OR REPLACE PROCEDURE InsereGenre (p_genre VARCHAR) AS
-- Déclaration des variables
v_genre_majuscules VARCHAR(20);
v_count INTEGER;
genre_existe EXCEPTION;
BEGIN
-- On met le paramètre en majuscules
v_genre_majuscules := UPPER(p_genre);
-- On vérifie que le genre n'existe pas déjà
SELECT COUNT(*) INTO v_count
FROM Genre WHERE code = v_genre_majuscules;
-- Si on n'a rien trouvé: on insère
IF (v_count = 0) THEN
INSERT INTO Genre (code) VALUES (v_genre_majuscules);
ELSE
RAISE genre_existe;
END IF;
EXCEPTION
WHEN genre_existe THEN
DBMS_OUTPUT.PUT_LINE('Le genre existe déjà en ' ||
v_count || ' exemplaire(s).');
END;
/
La procédure accepte des paramètres qui, comme les variables, sont typées. Le
corps de la procédure montre un exemple d’utilisation d’une fonction SQL
fournie par le système, ici la fonction UPPER qui prend une chaîne de
caractères en entrée et la renvoie mise en majuscules.
La requête SQL garantit que l’on obtient un et un seul n-uplet. Nous verrons
plus loin comment traiter le cas où le résultat de la requête est une table
contenant un nombre quelconque de n-uplets. Dans l’exemple ci-dessus on obtient toujours un
attribut donnant le nombre de n-uplets existants dans la table pour le code
que l’on veut insérer. Si ce nombre n’est pas nul, c’est que le genre existe
déjà dans la table, et on produit une « exception » avec la clause
RAISE EXCEPTION, sinon c’est que le genre n’existe pas et on peut
effectuer la clause d’insertion, en indiquant comme valeurs à insérer celles
contenues dans les variables appropriées.
On peut appeler cette procédure à partir de n’importe quelle
application connectée au SGBD. Sous SQL*Plus
on utilise l’instruction execute.
Voici par
exemple ce que l’on obtient avec deux appels successifs.
SQL> execute InsereGenre('Policier');
SQL> execute InsereGenre('Policier');
Le genre existe déjà en 1 exemplaire(s).
Le premier appel s’est correctement déroulé puisque le genre « Policier » n’existait pas encore dans la table. Le second en revanche a échoué, ce qui a déclenché l’exception et l’affichage du message d’erreur.
On peut appeler InsereGenre() depuis un programme C,
Java, ou tout autre outil. Si on se fixe comme règle de toujours
passer par cette procédure pour insérer dans la table Genre,
on est donc sûr que les contraintes implantées dans la procédure
seront toujours vérifiées.
Note
Pour forcer les développeurs à toujours passer par
la procédure, on peut fixer les droits d’accès de telle
sorte que les utilisateurs ORACLE aient le droit
d’exécuter InsereGenre(), mais pas de droit
de mise à jour sur la table Genre elle-même.
Voici un troisième exemple qui complète ce premier tour d’horizon rapide du langage. Il s’agit cette fois d’une fonction, la différence avec une procédure étant qu’elle renvoie une valeur, instance de l’un des types SQL. Dans l’exemple qui suit, la fonction prend en entrée l’identifiant d’un film et renvoie une chaîne de caractères contenant la liste des prénom et nom des acteurs du film, séparés par des virgules.
-- Fonction retournant la liste des acteurs pour un film donné
CREATE OR REPLACE FUNCTION MesActeurs(v_idFilm INTEGER) RETURN VARCHAR IS
-- Le résultat
resultat VARCHAR(255);
BEGIN
-- Boucle prenant tous les acteurs du films
FOR art IN
(SELECT Artiste.* FROM Role, Artiste
WHERE idFilm = v_idFilm AND idActeur=idArtiste)
LOOP
IF (resultat IS NOT NULL) THEN
resultat := resultat || ', ' || art.prenom || ' ' || art.nom;
ELSE
resultat := art.prenom || ' ' || art.nom;
END IF;
END LOOP;
return resultat;
END;
/
La fonction effectue une requête SQL pour rechercher tous les acteurs du film dont l’identifiant est passé en paramètre. Contrairement à l’exemple précédent, cette requête renvoie en général plusieurs n-uplets. Une des caractéristiques principales des techniques d’accès à une base de données avec un langage procédural est que l’on ne récupère pas d’un seul coup le résultat d’un ordre SQL. Il existe au moins deux raisons à cela :
- le résultat de la requête peut être extrêmement volumineux, ce qui poserait des problèmes d’occupation mémoire si on devait tout charger dans l’espace du programme client ;
- les langages de programmation ne sont en général pas équipés nativement des types nécessaires à la représentation d’un ensemble de n-uplets.
Le concept utilisé, plus ou moins implicitement, dans toutes les interfaces permettant aux langages procéduraux d’accéder aux bases de données est celui de curseur. Un curseur permet de parcourir, à l’aide d’une boucle, l’ensemble des n-uplets du résultat d’une requête, en traitant le n-uplet courant à chaque passage dans la boucle. Ici nous avons affaire à la version la plus simple qui soit d’un curseur, mais nous reviendrons plus loin sur ce mécanisme.
Une fonction renvoie une valeur, ce qui permet de l’utiliser dans une requête SQL comme n’importe quelle fonction native du système. Voici par exemple une requête qui sélectionne le titre et la liste des acteurs du film dont l’identifiant est 5.
SQL> SELECT titre, MesActeurs(idFilm) FROM Film WHERE idFilm=5;
TITRE MESACTEURS(IDFILM)
------------ -----------------------------
Volte/Face John Travolta, Nicolas Cage
On peut noter que le résultat de la fonction MesActeurs() ne peut pas être
obtenu avec une requête SQL. Il est d’ailleurs intéressant de se demander
pourquoi, et d’en tirer quelques conclusions sur certaines limites de SQL.
Il est important de mentionner également qu’ORACLE ne permet
pas l’appel, dans un ordre SELECT de fonctions
effectuant des mises à jour dans la base : une requête
n’est pas censée entraîner des modifications, surtout
si elles s’effectuent de manière transparente pour l’utilisateur.
Syntaxe de PL/SQL¶
Voici maintenant une présentation plus systématique du langage PL/SQL. Elle vise à expliquer et illustrer ses principes les plus intéressants et à donner les éléments nécessaires à une expérimentation sur machine mais ne couvre cependant pas toutes ses possibilités, très étendues.
Types et variables¶
PL/SQL reconnaît tous les types standard de SQL,
plus quelques autres dont le type Boolean
qui peut prendre les valeurs TRUE
ou FALSE. Il propose également deux constructeurs permettant de créer des types
composés :
- le constructeur
RECORDest comparable au schéma d’une table ; il décrit un ensemble d’attributs typés et nommés ;- le constructeur
TABLEcorrespond aux classiques tableaux unidimensionnels.
Le constructeur RECORD est particulièrement
intéressant pour représenter un n-uplet d’une table,
et donc pour définir des variables servant
à stocker le résultat d’une requête SQL. On peut
définir soit-même un type avec RECORD,
avec une syntaxe très similaire à celle du
CREATE TABLE.
DECLARE
-- Déclaration d'un nouveau type
TYPE adresse IS RECORD
(no INTEGER,
rue VARCHAR(40),
ville VARCHAR(40),
codePostal VARCHAR(10)
);
Mais PL/SQL offre également un mécanisme extrêmement utile consistant à dériver
automatiquement un type RECORD en fonction d’une table ou d’un
attribut d’une table. On utilise alors le nom de la table ou de l’attribut,
associées respectivement au qualificateur %ROWTYPE ou à
%TYPE pour désigner le type dérivé. Voici
quelques exemples :
Film.titre%TYPEest le titre de l’attributtitrede la tableFilm;Artiste%ROWTYPEest un typeRECORDcorrespondant aux attributs de la tableArtiste.
Le même principe de dérivation automatique d’un type s’applique également aux requêtes SQL définies dans le cadre des curseurs. Nous y reviendrons au moment de la présentation de ces derniers.
La déclaration d’une variable consiste à donner son nom, son type, à indiquer si
elle peut être NULL et a donner éventuellement
une valeur initiale. Elle est de la forme :
<nomVariable> <typeVariable> [NOT NULL] [:= <valeurDéfaut>]
Il est possible de définir également des constantes, avec la syntaxe :
<nomConstante> CONSTANT <typeConstante> := <valeur>
Toutes les déclarations de variables ou de constantes doivent être comprises dans
la section DECLARE. Toute variable non initialisée est à NULL.
Voici quelques exemples de déclarations. Tous
les noms de variables sont systématiquement
préfixés par v_. Ce n’est pas
une obligation mais ce type
de convention permet de distinguer plus
facilement les variables de PL/SQL des attributs
des tables dans les ordres SQL.
DECLARE
-- Constantes
v_aujourdhui CONSTANT DATE := SYSDATE;
v_pi CONSTANT NUMBER(7,5) := 3.14116;
-- Variables scalaires
v_compteur INTEGER NOT NULL := 1;
v_nom VARCHAR(30);
-- Variables pour un n-uplet de la table Film et pour le résumé
v_film Film%ROWTYPE;
v_resume Film.resume%TYPE;
Structures de contrôle¶
L’affectation d’une variable est effectuée par l’opérateur
:= avec la syntaxe :
<nomVariable> := <expression>;
où expression est toute expression valide retournant
une valeur de même type que celle de la variable. Rappelons
que tous les opérateurs SQL (arithmétiques, concaténation
de chaînes, manipulation de dates) et toutes les fonctions
du SGBD sont utilisables en PL/SQL. Un autre manière
d’affecter une variable est d’y transférer
tout ou partie d’un n-uplet provenant d’une
requête SQL avec la syntaxe :
SELECT <nomAttribut1>, [<nomAttribut2>, ...]
INTO <nomVariable1>, [<nomVariable2>, ... ]
FROM [...]
La variable doit être du même type que l’attribut correspondant de la clause SELECT, ce
qui incite fortement à utiliser le type dérivé avec %TYPE. Dès que l’on veut transférer
plusieurs valeurs d’attributs dans des variables, on a sans doute intérêt à utiliser un type
dérivé %ROWTYPE qui limite le
nombre de déclarations à effectuer. L’exemple suivant
illustre l’utilisation de la clause SELECT ... INTO
associée à des types dérivés. La fonction renvoie le titre
du film concaténé avec le nom du réalisateur.
-- Retourne une chaîne avec le titre du film et sont réalisateur
CREATE OR REPLACE FUNCTION TitreEtMES(v_idFilm INTEGER) RETURN VARCHAR IS
-- Déclaration des variables
v_titre Film.titre%TYPE;
v_idMES Film.idMES%TYPE;
v_mes Artiste%ROWTYPE;
BEGIN
-- Recherche du film
SELECT titre, idMES
INTO v_titre, v_idMES
FROM Film
WHERE idFilm=v_idFilm;
-- Recherche du metteur en scène
SELECT * INTO v_mes FROM Artiste WHERE idArtiste = v_idMES;
return v_titre || ', réalisé par ' || v_mes.prenom
|| ' ' || v_mes.nom;
END;
/
L’association dans la requête SQL de noms d’attributs et de noms de variables peut parfois s’avérer ambiguë d’où l’utilité d’une convention permettant de distinguer clairement ces derniers.
Les structures de test et de boucles sont tout à fait standard. La structure
conditionnelle est le IF dont la syntaxe est la suivante :
IF <condition> THEN
<instructions1>;
ELSE
<instruction2>;
END IF;
Les conditions sont exprimées comme dans une clause WHERE
de SQL, avec notamment la possibilité de tester si une valeur est à NULL, des opérateurs
comme LIKE et les connecteurs usuels AND, OR et NOT.
Le ELSE est optionnel, et peut éventuellement
être associé à un autre IF, selon la syntaxe généralisée suivante :
IF <condition 1> THEN
<instructions 1>;
ELSIF <condition 2> THEN
<instruction 2>;
[...]
ELSIF <condition n> THEN
<instruction n>;
ELSE
<instruction n+1>;
END IF;
Il existe trois formes de boucles : LOOP,
FOR et WHILE. Seules les deux dernières sont
présentées ici car elles suffisent à tous les besoins
et sont semblables aux structures habituelles.
La boucle WHILE répète un ensemble d’instructions
tant qu’une condition est vérifiée. La condition
est testée à chaque entrée dans la boucle. Voici la
syntaxe :
WHILE <condition> LOOP
<instructions>;
END LOOP;
Rappelons que les expressions booléennes en SQL peuvent prendre trois valeurs :
TRUE, FALSE et UNKNOWN quand l’évaluation de l’expression rencontre une
valeur à NULL. Une condition est donc vérifiée quand elle prend la valeur TRUE,
et une boucle WHILE s’arrête en cas de FALSE ou UNKNOWN.
La boucle FOR permet de répéter un ensemble
d’instructions pour chaque valeur d’un intervalle de nombres entiers.
La syntaxe est donnée ci-dessous. Notez les deux points
entre les deux bornes de l’intervalle, et la
possibilité de parcourir cet intervalle de haut en bas
avec l’option REVERSE.
FOR <variableCompteur> IN [REVERSE] <min>..<max> LOOP
<instructions>;
END LOOP;
Des itérations couramment utilisées en PL/SQL consistent à parcourir le résultat d’une requête SQL avec un curseur.
Structure du langage¶
Le code PL/SQL est structuré en blocs. Un bloc comprend trois sections
explicitement délimitées : les déclarations, les
instructions (encadrée par begin et end) et les exceptions,
placées en général à la fin de la section d’instruction. On peut partout
mettre des commentaires, avec deux formes possibles :
soit une ligne commençant par deux tirets --,
soit, comme en C/C++, un texte de longueur quelconque
compris entre /* et */. La structure générale d’un bloc
est donc la suivante :
[DECLARE]
-- Déclaration des variables, constantes, curseurs et exceptions
BEGIN
-- Instructions, requêtes SQL, structures de contrôle
EXCEPTION
-- Traitement des erreurs
END;
Le bloc est l’unité de traitement de PL/SQL. Un bloc peut être anonyme. Il commence alors
par l’instruction DECLARE, et ORACLE le compile et l’exécute dans la foulée au moment où
il est rencontré. Le premier exemple que nous avons donné est un bloc anonyme.
Un bloc peut également être nommé (cas des procédures et fonctions) et stocké.
Dans ce cas le DECLARE est remplacé par l’instruction CREATE.
Le SGBD stocke la procédure ou la fonction et l’exécute quand on
l’appelle dans le cadre d’un langage de programmation.
La syntaxe de création d’une procédure stockée est donnée ci-dessous.
CREATE [OR REPLACE] PROCEDURE <nomProcédure>
[(<paramètre 1>, ... <paramètre n>)] AS
[<déclarations<]
BEGIN
<instructions>;
[EXCEPTION
<gestionExceptions>;
]
END;
La syntaxe des fonctions est identique, à l’exception
d’un RETURN <type> précédant le AS
et indiquant le type de la valeur renvoyée.
Procédures et fonctions prennent en entrée
des paramètres selon la syntaxe suivante :
<nomParamètre> [IN | OUT | IN OUT] <type> [:= <valeurDéfaut>]
La déclaration des paramètres ressemble à celle des variables. Tous les types
PL/SQL sont acceptés pour les paramètres, notamment les types dérivés avec
%TYPE et %ROWTYPE, et on peut définir des valeurs par défaut. Cependant la longueur
des chaînes de caractères (CHAR ou VARCHAR)
ne doit pas être précisée pour les paramètres. La principale différence avec la déclaration
des variables est le mode d’utilisation des paramètres
qui peut être IN, OUT ou IN OUT. Le mode détermine la manière dont les paramètres
servent à communiquer avec le programme appelant :
INindique que la valeur du paramètre peut être lue mais pas être modifiée ; c’est le mode par défaut ;OUTindique que la valeur du paramètre peut être modifée mais ne peut pas être lue;IN OUTindique que la valeur du paramètre peut être lue et modifiée.
En d’autres termes les paramètres IN permettent au programme appelant de passer des valeurs
à la procédure, les paramètres OUT permettent à la procédure de renvoyer des valeurs
au programme appelant, et les paramètres IN OUT peuvent jouer les deux rôles.
L’utilisation des paramètres OUT permet à une fonction
ou une procédure de renvoyer plusieurs valeurs.
Gestion des erreurs¶
Les exceptions en PL/SQL peuvent être soit des erreurs renvoyées par le SGBD lui-même en cas
de manipulation incorrecte des données, soit des erreurs définies par le programmeur lui-même.
Le principe est que toute erreur rencontrée à l’exécution
entraîne la levée} (RAISE) d’une exception, ce qui amène le flux de l’exécution
à se dérouter vers la section EXCEPTION du bloc courant. Cette section rassemble les
actions (exception handlers) à effectuer pour chaque type d’exception rencontrée.
Voici quelques-unes des exceptions les plus communes
levées par le SGBD.
INVALID_NUMBER, indique une conversion impossible d’une chaîne de caractères vers un numérique ;INVALID_CURSOR, indique une tentative d’utiliser un nom de curseur inconnu ;NO_DATA_FOUND, indique une requête SQL qui ne ramène aucun n-uplet ;TOO_MANY_ROWS, indique une requêteSELECT ... INTOqui n’est pas traitée par un curseur alors qu’elle ramène plusieurs n-uplets.
Les exceptions utilisateurs doivent être définies dans la section de déclaration avec la syntaxe suivante.
<nomException> EXCEPTION;
On peut ensuite lever, au cours de l’exécution d’un bloc PL/SQL, les
exceptions, systèmes ou utilisateurs, avec l’instruction RAISE.
RAISE <nomException>;
Quand une instruction RAISE est rencontrée, l’exécution PL/SQL est dirigée vers la section
des exceptions, et recherche si l’exception levée fait l’objet d’un traitement particulier.
Cette section elle-même consiste en une liste de conditions de le forme :
WHEN <nomException> THEN
<traitementException>;
Si le nom de l’exception levée correspond à l’une des conditions de la liste,
alors le traitement correspondant est exécuté. Sinon c’est la section
OTHERS qui est utilisée. S’il n’y a pas de section gérant les
exceptions, l’exception est passée au programme appelant. La procédure
suivante montre quelques exemples d’exceptions.
-- Illustration des exceptions. La procédure prend un
-- identifiant de film, et met le titre en majuscules.
-- Les exceptions suivantes sont levées:
-- Exception système: NO_DATA_FOUND si le film n'existe pas
-- Exception utilisateur: DEJA_FAIT si le titre
-- est déjà en majuscule
CREATE OR REPLACE PROCEDURE TitreEnMajuscules (p_idFilm INT) AS
-- Déclaration des variables
v_titre Film.titre%TYPE;
deja_fait EXCEPTION;
BEGIN
-- Recherche du film. Une exception est levée si on ne trouve rien
SELECT titre INTO v_titre
FROM Film WHERE idFilm = p_idFilm;
-- Si le titre est déjà en majuscule, on lève une autre
-- exception
IF (v_titre = UPPER(v_titre)) THEN
RAISE deja_fait;
END IF;
-- Mise à jour du titre
UPDATE Film SET titre=UPPER(v_titre) WHERE idFilm=p_idFilm;
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('Ce film n''existe pas');
WHEN deja_fait THEN
DBMS_OUTPUT.PUT_LINE('Le titre est déjà en majuscules');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Autre erreur...');
END;
/
Voici quelques exécutions de cette procédure qui montrent comment les exceptions sont
levées selon le cas. On peut noter qu’ORACLE considère comme une erreur
le fait un ordre SELECT ne ramène aucun n-uplet,
et lève alors l’exception NO_DATA_FOUND.
SQL> execute TitreEnMajuscules(900);
Le film n'existe pas
SQL> execute TitreEnMajuscules(5);
SQL> execute TitreEnMajuscules(5);
Le titre est déjà en majuscules
Les curseurs¶
Comme nous l’avons indiqué précédemment, les curseurs constituent un mécanisme de base dans les programmes accèdant aux bases de données. Ce mécanisme repose sur l’idée de traiter un n-uplet à la fois dans le résultat d’une requête, ce qui permet notamment d’éviter le chargement, dans l’espace mémoire du client, d’un ensemble qui peut être très volumineux.
Le traitement d’une requête par un curseur a un impact sur le style de programmation et l’intégration avec un langage procédural, sur les techniques d’évaluation de requêtes, et sur la gestion de la concurrence d’accès. Ces derniers aspects sont traités dans d’autres chapitres. La présentation qui suit est générale pour ce qui concerne les concepts, et s’appuie sur PL/SQL pour les exemples concrets. L’avantage de PL/SQL est de proposer une syntaxe très claire et un ensemble d’options qui mettent bien en valeur les points importants.
Déclaration d’un curseur¶
Un curseur doit être déclaré dans la section DECLARE du bloc PL/SQL. En général on
déclare également une variable dont le type est dérivé de la définition du curseur. Voici un exemple
de ces deux déclarations associées :
-- Déclaration d'un curseur
CURSOR MonCurseur IS
SELECT * FROM Film, Artiste
WHERE idMES = idArtiste;
-- Déclaration de la variable
v_monCurseur MonCurseur%ROWTYPE;
Le type de la variable, MonCurseur%ROWTYPE, est le type automatiquement calculé par PL/SQL pour
représenter un n-uplet du résultat de la requête définie par le curseur MonCurseur. Ce typage
permet, sans avoir besoin d’effectuer des déclarations et d’énumérer de longues listes de variables
réceptrices au moment de l’exécution de la requête, de transférer très simplement chaque n-uplet du résultat
dans une structure du langage procédural. Nous verrons que les choses sont beaucoup plus laborieuses avec
un langage, comme le C, dont l’intégration avec SQL n’est pas du tout naturelle.
En général on utilise des curseurs paramétrés qui, comme leur nom
l’indique, intègrent dans la requête SQL une ou plusieurs variables dont les
valeurs, au moment de l’exécution, déterminent le résultat et donc l’ensemble
de n-uplets à parcourir. Enfin on peut, optionnellement, déclarer l’intention
de modifier les n-uplets traités par le curseur avec un UPDATE,
ce qui entraîne au moment de l’exécution quelques conséquences importantes sur
lesquelles nous allons revenir. La syntaxe générale d’un curseur est donc la
suivante :
CURSOR <nomCurseur> [(<listeParamètres>)]
IS <requête>
[FOR UPDATE]
Les paramètres sont indiqués comme pour une procédure, mais le mode doit toujours être IN
(cela n’a pas de sens de modifier le paramètre d’un curseur). Le
curseur suivant effectue la même jointure que précédemment, mais les films sont sélectionnés
sur l’année de parution grâce à un paramètre.
-- Déclaration d'un curseur paramétré
CURSOR MonCurseur (p_annee INTEGER) IS
SELECT * FROM Film, Artiste
WHERE idMES = idArtiste
AND annee = p_annee;
Une déclaration complémentaire est celle des variables
qui vont permettre de recevoir les n-uplets au fur et à
mesure de leur parcours. Le type dérivé d’un curseur
est obtenu avec la syntaxe <nomCurseur>\%ROWTYPE.
Il s’agit d’un type RECORD avec un champ
par correspondant à expression de la clause SELECT.
Le type de chaque champ est aisément déterminé par le système. Déterminer le nom du champ
est un peu plus délicat car la clause SELECT peut contenir des attributs (c’est le plus courant)
mais aussi des expressions construites sur ces attributs comme, par exemple, AVG(annee).
Il est indispensable dans ce dernier cas de donner
un alias à l’expression, qui deviendra le nom du champ dans le type dérivé. Voici un exemple
de cette situation :
-- Déclaration du curseur
CURSOR MonCurseur IS
SELECT prenom || nom AS nomRéalisateur, anneeNaiss, COUNT(*) AS nbFilms
FROM Film, Artiste
WHERE idMES = idArtiste
-- Déclaration d'une variable associée
v_realisateur MonCurseur%ROWTYPE;
Le type dérivé a trois champs, nommés respectivement nomRealisateur,
anneeNaiss et nbFilms.
Exécution d’un curseur¶
Un curseur est toujours exécuté en trois phases :
- ouverture du curseur (ordre
OPEN) ;- parcours du résultat en itérant des ordres
FETCHautant de fois que nécessaire ;- fermeture du curseur (
CLOSE).
Il faut bien être conscient de la signification de ces trois phases. Au moment du OPEN, le SGBD va analyser
la requête, construire un plan d’exécution (un programme d’accès aux fichiers) pour calculer le résultat, et initialiser
ce programme de manière à être en mesure de produire un n-uplet dès qu’un FETCH est reçu. Ensuite,
à chaque FETCH, le n-uplet courant est envoyé par le SGBD au curseur, et le plan d’exécution se prépare
à produire le n-uplet suivant.
En d’autres termes le résultat est déterminé au moment du OPEN, puis
exploité au fur est à mesure de l’appel des FETCH. Quelle que soit la
période sur laquelle se déroule cette exploitation (10 secondes, 1 heure ou une
journée entière), le SGBD doit assurer que les données lues par le curseur
refléteront l’état de la base au moment de l’ouverture du curseur. Cela
signifie notamment que les modifications effectuées par
d’autres utilisateurs, ou par le programme client (c’est-à-dire celui qui exécute le curseur) lui-même,
ne doivent pas être visibles au moment du parcours du résultat.
Les systèmes relationnels proposent différents niveaux d’isolation pour assurer ce type de comportement (pour en savoir plus, voir le chapitre sur la concurrence d’accès dans http://sys.bdpedia.fr). Il suffit d’imaginer ce qui se passerait si le curseur était sensible à des insertions, mises à jour ou suppressions effectuées pendant le parcours du résultat. Voici par exemple un pseudo-code montrant une situation où le parcours du curseur ne finirait jamais !
-- Un curseur qui s'exécute indéfiniment
OPEN du curseur sur la table T;
WHILE (FETCH du curseur ramène un n-upletdans T) LOOP
Insérer un nouveau n-uplet dans T;
END LOOP;
CLOSE du curseur;
Chaque passage dans le WHERE entraîne l’insertion d’un nouveau
n-uplet, et on se sortirait donc jamais de la boucle
si le curseur prenait en compte ce dernier.
D’autres situations, moins caricaturales, et résultant
d’actions effectuées par d’autres utilisateurs, poseraient des problèmes également. Le
SGBD assure que le résultat est figé au moment du OPEN puisque c’est à ce moment-là que la requête est constituée
et – au moins conceptuellement – exécutée.
Une solution triviale pour satisfaire cette contrainte est le
calcul complet du résultat au moment du OPEN,
et son stockage dans une table temporaire.
Cette technique présente cependant de nombreux
inconvénients :
- il faut stocker le résultat quelque part, ce qui est pénalisant s’il est volumineux ;
- le programme client doit attendre que l’intégralité du résultat soit calculé avant d’obtenir le premièr n-uplet ;
- si le programme client souhaite effectuer des mises à jour, il faut réserver des n-uplets qui ne seront peut-être traités que dans plusieurs minutes voire plusieurs heures.
Dire que le résultat est figé ou déterminé
à l’avance ne signifie par forcément qu’il est calculé et matérialisé quelque part.
Les chapitres consacrés à l’évaluation de requêtes et à la concurrence d’accès dans http://sys.bdpedia.fr
décrivent en détail
les techniques plus sophistiquées pour gérer les curseurs.
Ce qu’il faut retenir ici (et partout où nous parlerons de curseur), c’est que
le résultat d’une requête n’est pas forcément pré-calculé dans son intégralité
mais peut être construit, utilisé puis détruit au fur et à mesure de
l’itération sur les ordres FETCH.
Ce mode d’exécution explique certaines restrictions qui semblent étranges si on n’en est pas averti. Par exemple un curseur ne fournit pas d’information sur le nombre de n-uplets du résultat, puisque ces n-uplets, parcourus un à un, ne permettent pas de savoir à l’avance combien on va en rencontrer. De même, on ne sait pas revenir en arrière dans le parcours d’un résultat puisque les n-uplets produits ne sont parfois pas conservés.
Il existe dans la norme une option SCROLL indiquant que l’on peut
choisir d’aller en avançant ou en reculant sur l’ensemble des n-uplets. Cette
option n’est disponible dans aucun système, du moins à l’heure où ces lignes
sont écrites. Le SCROLL est problématique puisqu’il impose de
conserver au SGBD le résultat complet pendant toute la durée de vie du curseur,
l’utilisateur pouvant choisir de se déplacer d’avant en arrière sur l’ensemble
des n-uplets. Le SCROLL est difficilement compatible avec la technique
d’exécution employés dans tous les SGBD, et qui ne permet qu’un seul parcours
séquentiel sur l’ensemble du résultat.
Les curseurs PL/SQL¶
La gestion des curseurs dans PL/SQL s’appuie sur une syntaxe
très simple et permet, dans un grand nombre de cas, de limiter au maximum les déclarations et instructions
nécessaires. La manière la plus générale de traiter un curseur, une fois sa déclaration effectuée,
et de s’appuyer sur les trois instructions OPEN, FETCH et CLOSE dont
la syntaxe est donnée ci-dessous.
OPEN <nomCurseur>[(<valeursParamètres>)];
FETCH <nomCurseur> INTO <variableRéceptrice>;
CLOSE <nomCurseur>;
La (ou les) variable(s) qui suivent le INTO doivent correspondre au type d’un n-uplet du résultat.
En général on utilise une variable déclarée avec le type dérivé du curseur, <nomCurseur>%ROWTYPE.
Une remarque importante est que les curseurs ont l’inconvénient d’une part de consommer de la mémoire du côté serveur, et
d’autre part de bloquer d’autres utilisateurs si des n-uplets doivent être réservés
en vue d’une mise à jour (option FOR UPDATE). Une bonne habitude
consiste à effectuer le OPEN le plus tard possible, et le CLOSE le plus
tôt possible après le dernier FETCH.
Au cours de l’accès au résultat (c’est-à-dire après le premier FETCH
et avant le CLOSE), on peut obtenir les informations
suivantes sur le statut du curseur.
<nomCurseur>%FOUNDest un booléen qui vautTRUEsi le dernierFETCHa ramené un n-uplet ;<nomCurseur>%NOTFOUNDest un booléen qui vautTRUEsi le dernierFETCHn’a pas ramené de n-uplet ;<nomCurseur>%ROWCOUNTest le nombre de n-uplets parcourus jusqu’à l’état courant (en d’autres termes c’est le nombre d’appelsFETCH) ;<nomCurseur>%ISOPENest un boolén qui indique si un curseur a été ouvert.
Cela étant dit, le parcours d’un curseur consiste à l’ouvrir, à effectuer une boucle en effectuant
des FETCH tant que l’on trouve des n-uplets (et qu’on souhaite continuer le traitement), enfin
à fermer le curseur. Voici un exemple assez complet qui utilise un curseur paramétré pour parcourir
un ensemble de films et leurs metteur en scène pour une année donnée, en afichant à chaque FETCH
le titre, le nom du metteur en scène et la liste des acteurs.
Remarquez que cette liste est elle-même obtenu par
un appel à la fonction PL/SQL MesActeurs.
-- Exemple d'un curseur pour rechercher les films
-- et leur metteur en scène pour une année donnée
CREATE OR REPLACE PROCEDURE CurseurFilms (p_annee INT) AS
-- Déclaration d'un curseur paramétré
CURSOR MonCurseur (v_annee INTEGER) IS
SELECT idFilm, titre, prenom, nom
FROM Film, Artiste
WHERE idMES = idArtiste
AND annee = v_annee;
-- Déclaration de la variable associée au curseur
v_monCurseur MonCurseur%ROWTYPE;
-- Déclaration de la variable pour la liste des acteurs
v_mesActeurs VARCHAR(255);
BEGIN
-- Ouverture du curseur
OPEN MonCurseur(p_annee);
-- On prend le premier n-uplet
FETCH MonCurseur INTO v_monCurseur;
-- Boucle sur les n-uplets
WHILE (MonCurseur%FOUND) LOOP
-- Recherche des acteurs avec la fonction MesActeurs
v_mesActeurs := MesActeurs (v_monCurseur.idFilm);
DBMS_OUTPUT.PUT_LINE('Ligne ' || MonCurseur%ROWCOUNT ||
' Film: ' || v_monCurseur.titre ||
', de ' || v_monCurseur.prenom || ' ' ||
v_monCurseur.nom || ', avec ' || v_mesActeurs);
-- Passage au n-uplet suivant
FETCH MonCurseur INTO v_monCurseur;
END LOOP;
-- Fermeture du curseur
CLOSE MonCurseur;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Problème dans CurseurFilms : ' ||
sqlerrm);
END;
/
Le petit extrait d’une session sous SQL*Plus donné ci-dessous montre le résultat d’un appel à cette procédure pour l’année 1992.
SQL> set serveroutput on
SQL> execute CurseurFilms(1992);
Ligne 1 Film: Impitoyable, de Clint Eastwood, avec
Clint Eastwood, Gene Hackman, Morgan Freeman
Ligne 2 Film: Reservoir dogs, de Quentin Tarantino, avec
Quentin Tarantino, Harvey Keitel, Tim Roth, Chris Penn
La séquence des instructions OPEN, FETCH et CLOSE et la plus générale, notamment
parce qu’elle permet de s’arrêter à tout moment en interrompant la boucle.
On retrouve cette structure dans les langages de programmations
comme C, Java
et PHP. Elle a cependant l’inconvénient d’obliger à écrire deux instructions
FETCH, l’une avant l’entrée dans la boucle, l’autre à l’intérieur. PL/SQL propose une syntaxe
plus concise, basée sur la boucle FOR, en tirant partie de sa forte intégration avec SQL qui permet
d’inférer le type manipulé en fonction de la définition
d’un curseur. Cette variante de FOR se base sur la syntaxe suivante :
FOR <variableCurseur> IN <nomCurseur> LOOP
<instructions;
END LOOP;
L’économie de cette construction vient du fait qu’il n’est nécessaire ni de
déclarer la variable variableCurseur, ni d’effectuer un OPEN,
un CLOSE ou des FETCH. Tout est fait automatiquement
par PL/SQL, la variable étant définie uniquement dans le contexte
de la boucle. Voici un exemple qui montre également
comment traiter des mises sur les n-uplets sélectionnés.
-- Exemple d'un curseur effectuant des mises à jour
-- On parcourt la liste des genres, et on les met en majuscules,
-- on détruit ceux qui sont à NULL
CREATE OR REPLACE PROCEDURE CurseurMAJ AS
-- Déclaration du curseur
CURSOR CurseurGenre IS
SELECT * FROM Genre FOR UPDATE;
BEGIN
-- Boucle FOR directe: pas de OPEN, pas de CLOSE
FOR v_genre IN CurseurGenre LOOP
IF (v_genre.code IS NULL) THEN
DELETE FROM Genre WHERE CURRENT OF CurseurGenre;
ELSE
UPDATE Genre SET code=UPPER(code)
WHERE CURRENT OF CurseurGenre;
END IF;
END LOOP;
END;
/
Notez que la variable v_genre n’est pas déclarée explicitement.
Le curseur est défini avec une clause FOR UPDATE
qui indique au SGBD qu’une mise à jour peut être effectuée
sur chaque n-uplet. Dans ce cas – et dans ce cas seulement –
il est possible de faire référence au n-uplet courant,
au sein de la boucle FOR, avec
la syntaxe WHERE CURRENT OF <nomCurseur>.
Si on n’a pas utilisé la clause FOR UPDATE, il est possible de modifier (ou détruire) le n-uplet courant, mais
en indiquant dans le WHERE de la clause UPDATE la valeur de la clé. Outre la
syntaxe légèrement moins concise, cette désynchronisation
entre la lecture par le curseur, et la modification
par SQL, entraîne des risques d’incohérence (mise
à jour par un autre utilisateur entre le
OPEN et le FETCH)
qui sont développés dans le chapitre consacré
à la concurrence d’accès (http://sys.bdpedia.fr).
Il existe une syntaxe encore plus simple pour parcourir un curseur en PL/SQL. Elle consiste à ne
pas déclarer explicitement de curseur, mais à placer la requête SQL directement
dans la boucle FOR, comme par exemple :
FOR v_genre IN (SELECT * FROM Genre) LOOP
<instructions;
END LOOP;
Signalons pour conclure que PL/SQL traite toutes les requêtes SQL par des curseurs, que ce soit
des ordres UPDATE, INSERT, DELETE ou des requêtes SELECT
ne ramenant qu’une seule ligne. Ces curseurs sont
« implicites » car non déclarés par le programmeur,
et tous portent le même nom conventionnel,
SQL. Concrètement, cela signifie que
les valeurs suivantes sont définies
après une mise à jour par UPDATE, INSERT,
DELETE :
SQL%FOUNDvautTRUEsi la mise à jour a affecté au moins un n-uplet ;SQL%NOTFOUNDvautTRUEsi la mise à jour n’a affecté aucun n-uplet ;SQL%ROWCOUNTest le nombre de n-uplets affecté par la mise à jour ;SQL%ISOPENrenvoie systématiquementFALSEpuisque les trois phases (ouverture, parcours et fermeture) sont effectuées solidairement.
Le cas du SELECT est un peu différent : une exception
est toujours levée quand une recherche sans curseur
ne ramène pas de n-uplet (exception NO_DATA_FOUND)
ou en ramène plusieurs (exception TOO_MANY_ROWS).
Il faut donc être prêt à traiter ces exceptions pour ce type de requête. Par exemple, la recherche :
SELECT * INTO v_film
FROM Film
WHERE titre LIKE 'V%';
devrait être traitée par un curseur car il y n’y a pas de raison qu’elle ramène un seul n-uplet.
Triggers¶
Le mécanisme de triggers (que l’on peut traduire par « déclencheur » ou « réflexe ») est implanté dans les SGBD depuis de nombreuses années, et a été normalisé par SQL99. Un trigger est simplement une procédure stockée dont la particularité principale est de se déclencher automatiquement sur certains événements mise à jour spécifiés par le créateur du trigger.
On peut considérer les triggers comme une extension
du système de contraintes proposé par la clause
CHECK: à la différence de cette dernière, l’événement déclencheur est explicitement indiqué,
et l’action n’est pas limitée à la simple alternative acceptation/rejet. Les possibilités
offertes par les triggers
sont très intéressantes. Citons:
- la gestion des redondances; l’enregistrement automatique de certains évèvenements (auditing);
- la spécification de contraintes complexes liées à l’évolution des données (exemple: le prix d’une séance ne peut qu’augmenter);
- toute règle liée à l’environnement d’exécution (restrictions sur les horaires, les utilisateurs, etc.).
Les triggers sont discutés dans ce qui suit de manière générale, et illustrés par des exemples ORACLE. Il faut mentionner que la syntaxe de déclaration des triggers est suivie par la plupart des SGBD, les principales variantes se situant au niveau du langage permettant d’implanter la partie procédurale. Dans ce qui suit, ce langage sera bien entendu PL/SQL.
Principes des triggers¶
Le modèle d’exécution des triggers est basé sur la séquence événement-Condition-Action (ECA) que l’on peut décrire ainsi:
- un trigger est déclenché par un évènement, spécifié par le programmeur, qui est en général une insertion, destruction ou modification sur une table;
- la première action d’un trigger est de tester une condition: si cette condition ne s’évalue pas à
TRUE, l’exécution s’arrête;- enfin l’action proprement dite peut consister en toute ensemble d’opérations sur la base de données, effectuée si nécessaire à l’aide du langage procédural supporté par le SGBD.
Une caractéristique importante de cette procédure (action) est de pouvoir manipuler simultanément les valeurs ancienne et nouvelle de la donnée modifiée, ce qui permet de faire des tests sur l’évolution de la base.
Parmi les autres caractéristiques importantes, citons les deux suivantes. Tout d’abord un trigger peut être exécuté au choix une fois pour un seul ordre SQL, ou à chaque n-uplet concerné par cet ordre. Ensuite l’action déclenchée peut intervenir avant l’événement, ou après.
L’utilisation des triggers permet de rendre une base de données dynamique: une opération sur la base peut en déclencher d’autres, qui elles-mêmes peuvent entraîner en cascade d’autres réflexes. Ce mécanisme n’est pas sans danger à cause des risques de boucle infinie.
Prenons l’exemple suivant: on souhaite conserver au niveau de la
table Cinéma le nombre total de places (soit la
somme des capacités des salles). Il s’agit en principe
d’une redondance à éviter en principe, mais que l’on
peut gérer avec les triggers.
On peut en effet implanter un trigger au niveau Salle
qui, pour toute mise à jour, va aller modifier la
donnée au niveau Cinéma.
Maintenant il est facile d’imaginer une situation
où on se retrouve avec des triggers en cascade.
Prenons le cas d’une table Ville (nom, capacité)
donnant le nombre de places de cinéma dans la ville.
Maintenant, supposons que la ville gère l’heure de la première séance d’une salle: on aboutit à un cycle infini!
Syntaxe¶
La syntaxe générale de création d’un trigger est donnée ci-dessous.
CREATE [OR REPLACE] TRIGGER <nomTrigger>
{BEFORE | AFTER}
{DELETE | INSERT | UPDATE [of column, [, column] ...]}
[ OR {DELETE | INSERT | UPDATE [of column, [, column] ...]}] ...
ON <nomTable> [FOR EACH ROW]
[WHEN <condition]
<blocPLSQL>
On peut distinguer trois parties dans cette construction
syntaxique. La partie événement
est spécifiée après BEFORE ou AFTER,
la partie condition après WHEN
et la partie action correspond au bloc PL/SQL.
Voici quelques explications complémentaires sur ces trois
parties.
« Evénement », peut être ` BEFORE`` ou
AFTER, suivi deDELETE,UPDATEouINSERTséparés par desOR.« Condition »,
FOR EACH ROWest optionnel. En son absence le trigger est déclenché une fois pour toute requête modifiant la table, et ce sans condition.Sinon
<condition>est toute condition booléenne SQL. De plus on peut rérférencer les anciennes et nouvelles valeurs du tuple courant avec la syntaxenew.attributet `` old.attribut`` respectivement.« Action » est une procédure qui peut être implantée, sous Oracle, avec le langage PL/SQL. Elle peut contenir des ordres SQL mais pas de mise à jour de la table courante.
Les anciennes et nouvelles valeurs du tuple courant sont référencées par
:new.attret:old.attr.Il est possible de modifier
newetold. Par exemple:new.prix=500;forcera l’attributprixà 500 dans unBEFOREtrigger.
La disponibilité de new et old
dépend du contexte. Par exemple new est
à NULL dans un trigger déclenché
par DELETE.
Quelques exemples¶
Voici tout d’abord un exemple de trigger qui maintient
la capacité d’un cinéma à chaque mise à jour
sur la table Salle.
CREATE TRIGGER CumulCapacite
AFTER UPDATE ON Salle
FOR EACH ROW
WHEN (new.capacite != old.capacite)
BEGIN
UPDATE Cinema
SET capacite = capacite - :old.capacite + :new.capacite
WHERE nom = :new.nomCinema;
END;
Pour garantir la validité du cumul, il
faudrait créer des triggers sur les événements
UPDATE et INSERT. Une solution plus
concise (mais plus coûteuse) est de recalculer
systématiquement le cumul: dans ce cas
on peut utiliser un trigger qui se déclenche
globalement pour la requête:
CREATE TRIGGER CumulCapaciteGlobal
AFTER UPDATE OR INSERT OR DELETE ON Salle
BEGIN
UPDATE Cinema C
SET capacite = (SELECT SUM (capacite)
FROM Salle S
WHERE C.nom = S.nomCinema);
END;

Ce cours de Philippe Rigaux est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
Table des Matières
- Introduction
- Le modèle relationnel
- SQL, langage déclaratif
- SQL, langage algébrique
- SQL, final
- Conception d’une base de données
- Schémas relationnel
- Le langage PL/SQL
- Transactions
Recherche
Saisissez un ou plusieurs mots-clés.